CPU - Datapath and Controls
Deadline: November 15th 11:59:59 PM
Overview

For Part 2 of this project, you will continue to implement the CPU you built from Part 1 to support more instructions in RISC-V. Once you’ve completed this project, you’ll know essentially everything you need to build a computer from scratch with nothing but logic gates!
0) Obtaining the Files
In the Project 3 repository you created for Project 3-1, run git pull staff master to get the updated starter code for Part 2. (If you havent already, make sure you have run git remote add staff https://github.com/61c-teach/fa19-proj3-starter.git to add the staff starter code repo as a remote).
The updated starter code now includes 6 one stage sanity tests in the onestage-tests folder, 6 two stage sanity tests in the twostage-tests folder, a python file to generate your own test circuits create_test.py and a new my_tests folder, where the test circuits you create will be stored.
Resources
Some common sources of Logisim errors, for your debugging convenience:
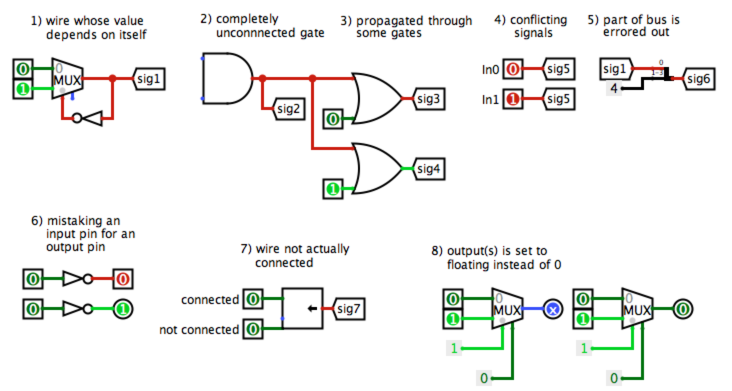
1) Processor
For Part 2, your completed processor (cpu.circ) should implement all of the instructions (not just addi) in the section Instruction Set Architecture (ISA) using a two-stage pipeline, with IF in the first stage and ID, EX, MEM, and WB in the second stage.
Once again, be careful NOT to move the input or output pins!
1.5) Memory
Again, here’s a quick summary of the inputs and outputs of the memory unit:
| Signal Name | Direction | Bit Width | Description |
|---|---|---|---|
| WriteAddr | Input | 32 | Address to read/write to in Memory |
| WriteData | Input | 32 | Value to be written to Memory |
| MemRW | Input | 1 | Equal to one on any instructions that write to Memory and zero otherwise |
| CLK | Input | 1 | Driven by the clock input to the CPU |
| ReadData | Output | 32 | Value of the data stored at the specified address |
Note that the address you give to memory is a byte address, but memory returns an entire word of memory. The memory unit ignores the bottom two bits of the address you provide to it, and treats its input as a word address rather than a byte address. For example, if you input the 32-bit address 0x0000_1007, it wil be treated as the word address 0x0000_0401, and you will get as output the 4 bytes at addresses 0x0000_1004, 0x0000_1005, 0x0000_1006, and 0x0000_1007.
A note about the lw, lh, and sw instructions: the RISC-V ISA supports unaligned accesses, but implementing them is complicated. We’ll only be implementing aligned memory accesses in this project. This means that lw and sw will only operate on addresses that are multiples of 4, and lh will only operate on addresses that are multiples of 2, and you should not implement unaligned accesses; you’ll most likely need to use stalling, which will result in your output not matching our expected output.
2) The Instruction Set Architecture
Your CPU will support the instructions listed below. Notice that this is not all of the instructions on the green card! These are the only instructions you will be tested on implementing. You will not be punished for implementing other instructions (the autograder will cover ONLY the instructions below).
Instruction Formats

The Instructions
| Instruction | Type | Opcode | Funct3 | Funct7/Immediate | Operation |
| add rd, rs1, rs2 | R | 0x33 | 0x0 | 0x00 | R[rd] ← R[rs1] + R[rs2] |
| mul rd, rs1, rs2 | 0x0 | 0x01 | R[rd] ← (R[rs1] * R[rs2])[31:0] | ||
| sub rd, rs1, rs2 | 0x0 | 0x20 | R[rd] ← R[rs1] - R[rs2] | ||
| sll rd, rs1, rs2 | 0x1 | 0x00 | R[rd] ← R[rs1] << R[rs2] | ||
| mulh rd, rs1, rs2 | 0x1 | 0x01 | R[rd] ← (R[rs1] * R [rs2])[63:32] | ||
| mulhu rd, rs1, rs2 | 0x3 | 0x01 | (unsigned) R[rd] ← (R[rs1] * R[rs2])[63:32] | ||
| slt rd, rs1, rs2 | 0x2 | 0x00 | R[rd] ← (R[rs1] < R[rs2]) ? 1 : 0 (signed) | ||
| xor rd, rs1, rs2 | 0x4 | 0x00 | R[rd] ← R[rs1] ^ R[rs2] | ||
| divu rd, rs1, rs2 | 0x5 | 0x01 | (unsigned) R[rd] ← R[rs1] / R[rs2] | ||
| srl rd, rs1, rs2 | 0x5 | 0x00 | R[rd] ← R[rs1] >> R[rs2] | ||
| or rd, rs1, rs2 | 0x6 | 0x00 | R[rd] ← R[rs1] | R[rs2] | ||
| remu rd, rs1, rs2 | 0x7 | 0x01 | (unsigned) R[rd] ← R[rs1] % R[rs2] | ||
| and rd, rs1, rs2 | 0x7 | 0x00 | R[rd] ← R[rs1] & R[rs2] | ||
| lb rd, offset(rs1) | I | 0x03 | 0x0 | R[rd] ← SignExt(Mem(R[rs1] + offset, byte)) | |
| lh rd, offset(rs1) | 0x1 | R[rd] ← SignExt(Mem(R[rs1] + offset, half)) | |||
| lw rd, offset(rs1) | 0x2 | R[rd] ← Mem(R[rs1] + offset, word) | |||
| addi rd, rs1, imm | 0x13 | 0x0 | R[rd] ← R[rs1] + imm | ||
| slli rd, rs1, imm | 0x1 | 0x00 | R[rd] ← R[rs1] << imm | ||
| slti rd, rs1, imm | 0x2 | R[rd] ← (R[rs1] < imm) ? 1 : 0 | |||
| xori rd, rs1, imm | 0x4 | R[rd] ← R[rs1] ^ imm | |||
| srli rd, rs1, imm | 0x5 | 0x00 | R[rd] ← R[rs1] >> imm | ||
| srai rd, rs1, imm | 0x5 | 0x20 | R[rd] ← R[rs1] >> imm | ||
| ori rd, rs1, imm | 0x6 | R[rd] ← R[rs1] | imm | |||
| andi rd, rs1, imm | 0x7 | R[rd] ← R[rs1] & imm | |||
| sw rs2, offset(rs1) | S | 0x23 | 0x2 | Mem(R[rs1] + offset) ← R[rs2] | |
| beq rs1, rs2, offset | SB | 0x63 | 0x0 |
if(R[rs1] == R[rs2])
PC ← PC + {offset, 1b0} |
|
| blt rs1, rs2, offset | 0x4 |
if(R[rs1] less than R[rs2] (signed))
PC ← PC + {offset, 1b0} |
|||
| bltu rs1, rs2, offset | 0x6 |
if(R[rs1] less than R[rs2] (unsigned))
PC ← PC + {offset, 1b0} |
|||
| bne rs1, rs2, offset | 0x1 |
if(R[rs1] != R[rs2])
PC ← PC + {offset, 1b0} |
|||
| lui rd, offset | U | 0x37 | R[rd] ← {offset, 12b0} | ||
| jal rd, imm | UJ | 0x6f |
R[rd] ← PC + 4
PC ← PC + {imm, 1b0} |
||
| jalr rd, rs1, imm | I | 0x67 | 0x0 |
R[rd] ← PC + 4
PC ← R[rs1] + {imm} |
For I, S, B, U, and J type instructions, you will have to extract the appropriate immediate from the instruction. We highly recommend that you create an Immediate Generator subcircuit to do this. Remember that in RISC-V, all immediates that leave the immediate generator are 32-bits and sign-extended! You may find the following diagram helpful for thinking about how to create the appropriate immediate for each type:

3) Controls
In order to correctly identify each instruction, control signals play a very important part in this project. Figuring out all of the control signals may seem intimidating. We suggest taking a look at the lecture slides to get started, and to remember that there is not a definitive set of control signals–walk through the datapath with different types of instructions, and when you see a MUX or other component think about what selector/enable value you will need for that instruction. We suggest you create a “Control Module” subcircuit that takes in an instruction and outputs the control signals for that instruction.
There are a two major approaches to implementing the Control so that it can translate the opcode/funct3/funct7 to the corresponding instruction and then set the control signals.
The recommended method is hard-wired control, as discussed in lecture, which is usually the preferred approach for RISC architectures like MIPS and RISC-V. Hard-wired control uses “AND”, “OR”, and “NOT” gates (along with the various components we’ve learned can be built from these gates, like MUXes and DEMUXes) to produce the appropriate control signals. The instruction decoder takes in an instruction and outputs all of the control signals for that instruction.
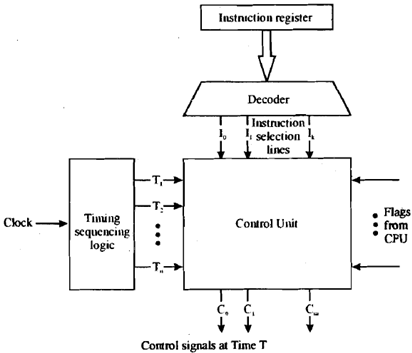
The other way to do it is to use ROM control. Every instruction implemented by a processor maps to an address in a ROM (read-only memory) unit. At that address in the ROM is the control word for that instruction. An address decoder takes in an instruction and outputs the address of the control word for that instruction. This approach is common in CISC architectures like Intel’s x86-64, and in real life, offers some flexibility because it can be re-programmed by changing the contents of the ROM.
4) Pipelining
For Part 2, in addition to the simple 2-stage pipeline you implemented in Part 1, you will need to handle control hazards for branch instruction.
The instruction immediately after a branch or jump is not executed if a branch is taken. This makes your task a bit more complex. By the time you have figured out that a branch or jump is in the execute stage, you have already accessed the instruction memory and pulled out (possibly) the wrong instruction. You will therefore need to “kill” instruction that is being fetched if the instruction under execution is a jump or a taken branch.
Instruction kills for this project MUST be accomplished by MUXing a nop into the instruction stream and sending the nop into the Execute stage instead of using the fetched instruction. Notice that 0x00000013, or addi x0, x0, 0 is a nop instruction; other nop instructions will work too. You should only kill if a branch is taken (do not kill otherwise). Do kill on every type of jump.
Do not solve this issue by calculating branch offsets in the IF stage. Because we test your output against the reference every cycle, and the reference returns a nop, while it may be a conceptually correct solution, this will cause you to fail our tests.
Because all of the control and execution is handled in the Execute stage, your processor should be more or less indistinguishable from a single-cycle implementation, barring the one-cycle startup latency and the branch/jump delays. However, we will be enforcing the two-stage pipeline design. Some things to consider:
- Will the IF and EX stages have the same or different
PCvalues? - Do you need to store the
PCbetween the pipelining stages? - To MUX a
nopinto the instruction stream, do you place it before or after the instruction register? - What address should be requested next while the EX stage executes a
nop? Is this different than normal?
You might also notice a bootstrapping problem here: during the first cycle, the instruction register sitting between the pipeline stages won’t contain an instruction loaded from memory. How do we deal with this? It happens that Logisim automatically sets registers to zero on reset; the instruction register will then contain a nop. We will allow you to depend on this behavior of Logisim. Remember to go to Simulate --> Reset Simulation (Ctrl+R) to reset your processor.
After pipelining your processor, you should run the ./cpu-twostage-sanity.sh test instead of the single-stage version.
Testing
Sanity Tests
We’ve included 6 sanity tests for you with the starter code. You can run them using ./cpu-twostage-sanity.sh
Six sanity tests have been included for you with the starter code: CPU-addi.circ, CPU-add_lui_sll.circ, CPU-mem.circ, CPU-branch.circ, CPU-br_jalr.circ, and CPU-jump.circ. You can see the .s files and hex corresponding to each of these tests in the part2-tests/input directory. Run them using the following command from your main Project 3-2 directory:
$ ./cpu-twostage-sanity.sh
Like in Project 3-1, we’ve included a Python script to make it a bit easier to interpret your test output. It’s called binary_to_hex.py. It is in the root directory also in twostage-tests/circ_files directory. You can run it on the reference output for CPU-addi.circ with the following command:
$ python binary_to_hex.py twostage-tests/circ_files/reference_output/CPU-addi.out
or, on your CPU’s output with the following command:
$ python binary_to_hex.py twostage-tests/circ_files/output/CPU-addi.out
If you haven’t yet successfully implemented the pipeline, we’ve also included one-stage sanity tests. We highly recommend that you implement the pipeline before implementing your whole CPU – pipelining is one of the most important concepts to take away from this project, implementing pipelining will make it easier for you to test, and having a pipelined CPU will maximize your grade on the project.
Writing your own tests
The autograder tests fall into 3 main categories: unit tests, integration tests, and edge case tests. We won’t be revealing to you what these tests are specifically, but you should be able to re-create a very close approximation of them on your own in order to test your datapath.
What is a unit test? A unit test exercises your datapath with a single instruction, to make sure that each individual instruction has been implemented and is working as expected. You should write a different unit test for every single instruction that you need to implement, and make sure that you test the spectrum of possibilities for that instruction thoroughly. For example, a unit test slt should contain cases where rs1 < rs2, rs1 > rs2, and where rs1 == rs2.
What is an integration test? After you’ve passed your unit tests, move onto tests that use multiple functions in combination. Try out various simple RISC-V programs that run a single function; your CPU should be able to handle them, if working properly. Feel free to try to use riscv-gcc to compile C programs to RISC-V, but be aware of the limited instruction set we’re working with (you don’t have any ecall instructions, for example). We’d recommend that you instead try to write simple functions on your own based on what you’ve seen in labs, discussions, projects, and exams.
Finally, edge cases! What edge cases should you look for? A hint from us: our 2 main classes of edge cases come from memory operations and branch/jump operations (we call them something along the lines of “mem-full” and “br-jump-edge”). Think about all the different ways these operations could go wrong.
Creating your tests
For this project, we will not be releasing all the tests. However, we have included some scripts to make test creation a little bit easier on you for two-stage processors. Included in the starter code is a file called create_test.py. As its arguments, it expectes the names of the .s files containing the RISC-V code you wish to test. The script will then generate copies of run.circ with your new tests loaded in for you, along with some other files. For everything to work properly:
- Write your tests and name them whatever you would like, but be sure to save them as .s files
- Don’t move the tests anywhere, keep them (as well as
create_test.py) in the root directory of the project - Run:
$ python3 create_test.py <test 1 name here>.s <test 2 name here>.s ...
Your file hierarchy should now contain some new things:
fa19-proj3-2-starter
-- <test name here>.s # Your test
-- my_tests
-- circ_files
-- <alu, cpu, mem, regfile>.circ # All your circuits
-- output
-- reference_output
-- CPU-<test name here>.circ # The new circuit containing your test
-- input
-- <test name here>.hex # The hex dissasembly of your test
-- <test name here>.s # A copy of your test
Now that everything is created, to test your own tests, run:
$ ./cpu-part2-user.sh
If you wish to delve into your the circuit running your test, you can simulate it by opening up the CPU-<test name here>.circ file. If you don’t remember how to simulate your circuit, please refer back to the Logism lab. We highly encourage you to poke your circuit while the test is running to observe how your circuit reacts to various inputs (perhaps this can give you ideas for new tests to write).
If you wish to simulate your code only for a certain number of cycles, you can do that by running the following:
$ python3 create_test.py <test name here>.s -n <number of cycles>
If you would like to decode your output, use the provided binary_to_hex.py on the appropriate .out file in the output folder shown above. Be aware that because you’re implementing a 2-stage pipelined processor and the first instruction writes on the rising edge of the second clock cycle, the effects of your instructions will have a 2 instruction delay. For example, let’s say I have written a test with one instruction:
addi t0, x0, 1
The output will actually come out to be:

Note how t0 doesn’t get changed until line 3.
Test Coverage
We’ve created a Gradescope autograder to examine your test coverage. It will be released shortly.
To submit to it, upload a zip file that has all of your .s files in it. The autograder will output a message about the percentage coverage of your tests against our staff suite of tests, or if your test raised a Syntax Error, a message to help you debug why it happened.
Our test coverage autograder is significantly less accepting of syntax variations than Venus. Please make sure that:
- Your immediates are in decimal, not in hex (e.g. not 0x00F, but 15)
- Your memory instructions are properly formatted, e.g.
sw rs2 0(rs1), notsw rs1 rs2 0(or any sort of variation) - All of your branch and jump instructions use labels, not raw immediates
- You do not use pseudoinstructions of any sort. For example,
jal label, should bejal x0 label, andretshould bejalr x0 ra 0
And some general advice:
- If you make many short test files rather than one large one, it will be easier to figure out which test and which line causes your Syntax Error (and to figure out where your CPU is failing). We’d recommend that for unit testing, you have one .s file testing each instruction.
- Make sure you test every single instruction in the ISA, including the ones that are covered by the sanity tests; feel free to use the sanity tests as a model or even incorporate them as part of your test suite.
- Make sure you check that every single register is working.
- Make sure you don’t have any “dummy” tests: every test should lead to a change in state or register value; otherwise it is not a meaningful test.
- Use only the registers we told you to implement: x0, x1, x2, x5, x6, x7, x8, x9, x10.
Grading
25% of Project 3 was Project 3-1, the RegFile, ALU, and addi instruction. There was a potential for 3% extra credit if you implemented signed mulh properly. The remaining 75% comes from Project 3-2. Of this 75%, 25% comes from the public sanity tests, 40% comes from the hidden unit, edge case, and integration tests, and 10% will come from your Test Coverage score. We may potentially release an additional challenge worth some extra credit points later in the week, so watch out for that if you’re interested!
It is possible to receive the 25% for sanity tests while only creating a single-stage processor, but to receive points on the hidden tests, your processor must be a two-stage processor that is pipelined as described above. We have outlined our approach to testing in the Testing section, and if you write a thorough suite of your own tests, you should be able to pass all of the autograder tests.
Submission
Submission of the project itself will be through Gradescope, to the “Project 3 Part B” autograder assignment. The only files you should be editing are cpu.circ, alu.circ, and regfile.circ. When you upload your code, we will grab these files only, combine them with a default version of run.circ and mem.circ, and run tests on them. The public sanity tests that are run on Gradescope are identical to the cpu-onestage-sanity.sh and cpu-twostage-sanity.sh tests.
Be sure not to make any edits to run.circ or mem.circ, or else your files will not work in the autograder! Also be sure not to modify any of the given inputs and outputs of cpu.circ or else the autograder will likely fail for you.
Be sure to separately submit your test suite to the Test Coverage autograder so that you get your points.