Lab 11
Deadline: EOD Tuesday, April 16th
Objectives:
- TSW learn about and use various SIMD functions to perform data level parallelism
- TSW write code to SIMD-ize certain functions
- TSW learn about loop-unrolling and why it works
- TSW learn about OpenMP and thread level parallelism
- TSWBAT apply these concepts and compare their performances
Setup
Pull the Lab 11 files from the lab starter repository with
git pull staff master
Disclaimer
NOTE THAT ALL CODE USING SSE INSTRUCTIONS IS GUARANTEED TO WORK ON THE HIVE MACHINES AND IT MAY NOT WORK ELSEWHERE
Many newer processors support SSE intrinsics, so it is certainly possible that your machine will be sufficient, but you may not see accurate speedups. Ideally, you should ssh into one of the hive machines to run this lab. Additionally, many of the performance characteristics asked about later on this lab are more likely to show up on the Hive.
Exercise 1 - Familiarize Yourself with the SIMD Functions
Given the large number of available SIMD intrinsics we want you to learn how to find the ones that you’ll need in your application.
For this mini-exercise, we ask you to look at the Intel Intrinsics Guide. Open this page and once there, click the checkboxes for everything that begins with “SSE”.
Look through the possible instructions and syntax structures, then try to find the 128-bit intrinsics for the following operations:
- Four floating point divisions in single precision (i.e. float)
- Sixteen max operations over signed 8-bit integers (i.e. char)
- Arithmetic shift right of eight signed 16-bit integers (i.e. short)
Hint: Things that say “epi” or “pi” deal with integers, and those that say “ps” or “pd” deal with s ingle p recision and d ouble p recision floats.
Additionally, you can visualize how the vectors and the different functions work together by inputting your code into the code environment at this link!
Exercise 2 - Writing SIMD Code
For this part of the lab, we will be working in the simd directory
Common Little Mistakes
The following are bugs that the staff have noticed were preventing students from passing the tests (bold text is what you should not do):
- Trying to store your sum vector into a
long long intarray. Use an int array. Side note: why?? The return value of this function is indeed along long int, but that’s because anintisn’t big enough to hold the sum of all the values across all iterations of the outer loop. However, it is big enough to hold the sum of all the value across a single iteration of the outer loop. This means you’ll want to store your sum vector into anintarray after every iteration of the outer loop and add the total sum to the final resultresult. - Re-initializing your sum vector. Make sure when you add to your running sum vector, you aren’t declaring a new sum vector!!
- Forgetting the CONDITIONAL in the tail case!
- Adding to an UNINITIALIZED array! If you add stuff to your result array without initializing it, you are adding stuff to garbage, which makes the array still garbage! Using
storeubefore adding stuff is okay though.
We’ve got one header file common.h that has some code to sum the elements of a really big array. It’s a minor detail that it randomly does this 1 << 16 times… but you don’t need to worry about that. We also pincer the execution of the code between two timestamps (that’s what the clock() function does) to measure how fast it runs! The file simd.c is the one which will have a main function to run the sum functions.
Task
We ask you to vectorize/SIMDize the following code in common.h to speed up the naive implementation of sum().
You only need to vectorize the inner loop with SIMD! You will also need to use the following intrinsics:
__m128i _mm_setzero_si128()- returns a 128-bit zero vector__m128i _mm_loadu_si128(__m128i *p)- returns 128-bit vector stored at pointer p__m128i _mm_add_epi32(__m128i a, __m128i b)- returns vector (a_0 + b_0, a_1 + b_1, a_2 + b_2, a_3 + b_3)void _mm_storeu_si128(__m128i *p, __m128i a)- stores 128-bit vector a into pointer p__m128i _mm_cmpgt_epi32(__m128i a, __m128i b)- returns the vector (a_i > b_i ?0xffffffff : 0x0forifrom 0 to 3). AKA a 32-bit all-1s mask if a_i > b_i and a 32-bit all-0s mask otherwise__m128i _mm_and_si128(__m128i a, __m128i b)- returns vector (a_0 & b_0, a_1 & b_1, a_2 & b_2, a_3 & b_3), where & represents the bit-wise and operator
Start with the code in sum() and use SSE intrinsics to implement the sum_simd() function.
How do I do this?
Recall that the SSE intrinsics are basically functions which perform operations on multiple pieces of data in a vector in parallel. This turns out to be faster than running through a for loop and applying the operation once for each element in the vector.
In our sum function, we’ve got a basic structure of iterating through an array. On every iteration, we add an array element to a running sum. To vectorize, you should add a few array elements to a sum vector in parallel and then consolidate the individual values of the sum vector into our desired sum at the end.
- Hint 1:
__m128iis the data type for Intel’s special 128-bit vector. We’ll be using them to encode 4 (four) 32-bit ints. - Hint 2: We’ve left you a vector called
_127which contains four copies of the number 127. You should use this to compare with some stuff when you implement the condition within the sum loop. - Hint 3: DON’T use the store function (
_mm_storeu_si128) until after completing the inner loop! It turns out that storing is very costly and performing a store in every iteration will actually cause your code to slow down. However, if you wait until after the outer loop completes you may have overflow issues. - Hint 4: It’s bad practice to index into the
__m128ivector like they are arrays. You should store them into arrays first with thestoreufunction, and then access the integers elementwise by indexing into the array. - Hint 5: READ the function declarations in the above table carefully! You’ll notice that the loadu and storeu take
__m128i*type arguments. You can just cast an int array to a__m128ipointer. Alternatively, you could skip the typecast at the cost of a bunch of compiler warnings.
To compile and run your code, run the following commands:
make simd
./simd
Sanity check: The naive version runs at about 25 seconds on the hive machines, and your SIMDized version should run in about 5-6 seconds. The naive function may take a long time to run! Feel free to comment it out while you are implementing sum_simd(), but make sure to uncomment it out later, since we rely on that result for comparing against a reference; sometimes code can take a long time to run and this is one of those cases.
Checkpoint
- Show your TA your working code and performance improvement from
sumtosum_simd
Exercise 3 - Loop Unrolling
Concept Time! Another tactic used to increase performance is to unroll our for loops! By performing more operations per iteration of the for loop, we have to loop less and not have to waste as many cycles (think about why we would have to waste some cycles?). Theoretically, code would be faster if we didn’t create loops and just copy pasted the loop n times, but that’s not a very pretty function.
For example, consider this very simple example that adds together the first n elements of an array arr:
int total = 0;
for (int i = 0; i < n; i++) {
total += arr[i];
}
The corresponding assembly code might look something like this:
add t0, x0, x0
add t1, x0, x0 // Initialize loop counter
loop: beq t0, a1, end // Assume register a1 contains the size n of the array
slli t2, t1, 2
add t2, t1, a0 // Assume register a0 contains a pointer to the beginning of the array
lw t3, 0(t2) // Load arr[i] into t3
add t0, t3, t0 // total += arr[i]
addi t1, t1, 1 // Increment the loop counter
jal x0, loop
end: ...
If we unroll the loop 4 times, this would be our equivalent code, with a tail case for the situations where n is not a multiple of 4:
int total = 0;
for (int i = 0; i < n / 4 * 4; i+=4) {
total += arr[i];
total += arr[i + 1];
total += arr[i + 2];
total += arr[i + 3];
}
for (i = n / 4 * 4; i < n; i++) {
total += arr[i];
}
For the unrolled code, the corresponding assembly code might look something like this:
add t0, x0, x0
add t1, a1, x0 // Assume register a1 contains the size n of the array
srli t1, t1, 2
slli t1, t1, 2 // Find largest of multiple 4 <= n
add t2, x0, x0 // Initialize loop counter
loop: beq t2, t1, tail
slli t3, t2, 2
add t3, t3, a0 // Assume register a0 contains a pointer to the beginning of the array
lw t4, 0(t3) // Load arr[i] into t3
add t0, t4, t0 // total += arr[i]
lw t4, 4(t3) // Load arr[i + 1] into t3
add t0, t4, t0
lw t4, 8(t3), t0 // Load arr[i + 2] into t3
add t0, t4, t0
lw t4, 12(t3), // Load arr[i + 3] into t3
add t0, t4, t0
addi t2, t2, 4 // Increment the loop counter
jal x0, loop
tail: beq t2, a1, end
slli t3, t2, 2
lw t4, 0(t3)
add t0, t4, t0
addi t2, t2, 1
end: ...
To obtain even more performance improvement, carefully unroll the SIMD vector sum code that you created in the previous exercise to create sum_simd_unrolled(). This should get you a little more increase in performance from sum_simd (a few fractions of a second). As an example of loop unrolling, consider the supplied function sum_unrolled()
Task
Within common.h, copy your sum_simd() code into sum_simd_unrolled() and unroll it 4 (four) times. Don’t forget about your tail case!
To compile and run your code, run the following commands:
make simd
./simd
Checkpoint
- Show your TA your working code and performance improvement from
sum_simd()tosum_simd_unrolled(). - Explain why looping less, but doing more per loop still allows us to perform our code faster.
Exercise 4 - OpenMP Hello World
From this point onward, we’ll be working in the openmp directory:
For this lab, we will use C to leverage our prior programming experience with it. OpenMP is a framework with a C interface, and it is not a built-in part of the language. Most OpenMP features are actually directives to the compiler. Consider the following implementation of Hello World (hello.c):
int main() {
#pragma omp parallel
{
int thread_ID = omp_get_thread_num();
prinft(" hello world %d\n", thread_ID);
}
}
This program will fork off the default number of threads and each thread will print out “hello world” in addition to which thread number it is. You can change the number of OpenMP threads by setting the environment variable OMP_NUM_THREADS or by using the omp_set_num_threads function in your program. The #pragma tells the compiler that the rest of the line is a directive, and in this case it is omp parallel. omp declares that it is for OpenMP and parallel says the following code block (what is contained in { }) can be executed in parallel. Give it a try:
make hello
./hello
If you run ./hello a couple of times, you should see that the numbers are not always in numerical order and will most likely vary across runs. This is because within the parallel region, OpenMP does the code in parallel and as a result does not enforce an ordering across all the threads. It is also vital to note that the variable thread_ID is local to a specific thread and not shared across all threads. In general with OpenMP, variables declared inside the parallel block will be private to each thread, but variables declared outside will be global and accessible by all the threads.
Exercise 5 - Vector Addition
Vector addition is a naturally parallel computation, so it makes for a good first exercise. The v_add function inside v_add.c will return the array that is the cell-by-cell addition of its inputs x and y. A first attempt at this might look like:
void v_add(double* x, double* y, double* z) {
#pragma omp parallel
{
for(int i=0; i<ARRAY_SIZE; i++)
z[i] = x[i] + y[i];
}
}
You can run this (make v_add followed by ./v_add) and the testing framework will automatically time it and vary the number of threads. You will see that this actually seems to do worse as we increase the number of threads. The issue is that each thread is executing all of the code within the omp parallel block, meaning if we have 8 threads, we will actually be adding the vectors 8 times. DON’T DO THIS! To get speedup when increasing the number of threads, we need each thread to do less work, not the same amount as before. Rather than have each thread run the entire for loop, we need to split up the for loop across all the threads so each thread does only a portion of the work:
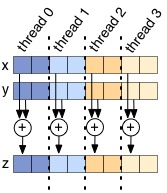
Your task is to modify v_add.c so there is some speedup (speedup may plateau as the number of threads continues to increase). To aid you in this process, two useful OpenMP functions are:
int omp_get_num_threads();int omp_get_thread_num();
The function omp_get_num_threads() will return how many threads there are in a omp parallel block, and omp_get_thread_num() will return the thread ID.
Divide up the work for each thread through two different methods (write different code for each of these methods):
- First task, slicing: have each thread handle adjacent sums: i.e. Thread 0 will add the elements at indices
isuch thati % omp_get_num_threads()is0, Thread 1 will add the elements wherei % omp_get_num_threads()is1, etc. - Second task, chunking: if there are N threads, break the vectors into N contiguous chunks, and have each thread only add that chunk (like the figure above).
Hints:
- Use the two functions we listed above somehow in the for loop to choose which elements each thread handles.
- You may need a special case to prevent going out of bounds for
v_add_optimized_chunks. Don’t be afraid to write one. - As you’re working on this exercise, you should be thinking about false sharing–read more here and here.
Fact: For this exercise, we are asking you to manually split the work amongst threads. Since this is such a common pattern for software, the designers of OpenMP actually made the #pragma omp for directive to automatically split up independent work. Here is the function rewritten using it. You may NOT use this directive in your solution to this exercise.
void v_add(double* x, double* y, double* z) {
#pragma omp parallel
{
#pragma omp for
for(int i=0; i<ARRAY_SIZE; i++)
z[i] = x[i] + y[i];
}
}
Test your code with:
make v_add
./v_add
Checkpoint
- Show the TA or AI checking you off your code for both optimized versions of
v_addthat manually splits up the work. Remember, you should not have used#pragma ompfor here. - Run your code to show that it gets parallel speedup.
- Which version of your code runs faster, chunks or adjacent? What do you think the reason for this is? Explain to the person checking you off.
Exercise 6 - Dot Product
The next interesting computation we want to compute is the dot product of two vectors. At first glance, implementing this might seem not too different from v_add, but the challenge is how to sum up all of the products into the same variable (reduction). A sloppy handling of reduction may lead to data races: all the threads are trying to read and write to the same address simultaneously. One solution is to use a critical section. The code in a critical section can only be executed by a single thread at any given time. Thus, having a critical section naturally prevents multiple threads from reading and writing to the same data, a problem that would otherwise lead to data races. A naive implementation would protect the sum with a critical section, like (dotp.c):
double dotp(double* x, double* y) {
double global_sum = 0.0;
#pragma omp parallel
{
#pragma omp for
for(int i=0; i<ARRAY_SIZE; i++)
#pragma omp critical
global_sum += x[i] * y[i];
}
return global_sum;
}
Try out the code (make dotp and ./dotp). Notice how the performance gets much worse as the number of threads goes up? By putting all of the work of reduction in a critical section, we have flattened the parallelism and made it so only one thread can do useful work at a time (not exactly the idea behind thread-level parallelism). This contention is problematic; each thread is constantly fighting for the critical section and only one is making any progress at any given time. As the number of threads goes up, so does the contention, and the performance pays the price. Can you fix this performance bottleneck?
Hint: REDUCE the number of times that each thread needs to use a critical section!
- First task: try fixing this code without using the OpenMP Reduction keyword. Hint: Try reducing the number of times a thread must add to the shared
global_sumvariable. - Second task: fix the problem using OpenMP’s built-in Reduction keyword (Google for more information on it). Is your performance any better than in the case of the manual fix? Why or why not?
Note: The exact syntax for using these directives can be kind of confusing. Here are the key things to remember:
- A
#pragma omp parallelsection should be specified with curly braces around the block of code to be parallelized. - A
#pragma ompfor section should not be accompanied with extra curly braces. Just stick that directive directly above aforloop.
Hint: You’ll need to type the ‘+’ operator somewhere when using reduction.
Hint: If you used the reduction keyword correctly, your code should no longer contain #pragma omp critical.
Finally, run your code to examine the performance:
make dotp
./dotp
Checkpoint
- Show the TA or AI checking you off your manual fix to
dotp.cthat gets speedup over the single threaded case. - Show the TA or AI checking you off your Reduction keyword fix for
dotp.c, and explain the difference in performance, if there is any. - Run your code to show the speedup.
Checkoff
Exercise 1:
- Record the 3 (three) intrinsics we specified above in a text file(or just know what they are) to show your TA.
Exercise 2:
- Show your TA your working code and performance improvement from
sumtosum_simd.
Exercise 3:
- Show your TA your working code and performance improvement from
sum_simd()tosum_simd_unrolled(). - Explain why looping less, but doing more per loop still allows us to perform our code faster.
Exercise 4:
- Nothing to show
Exercise 5:
- Show the TA or AI checking you off your code for both optimized versions of
v_addthat manually splits up the work. Remember, you should not have used#pragma omp forhere. - Run your code to show that it gets parallel speedup.
- Which version of your code runs faster, chunks or adjacent? What do you think the reason for this is? Explain to the person checking you off.
Exercise 6:
- Show the TA or AI checking you off your manual fix to
dotp.cthat gets speedup over the single threaded case. - Show the TA or AI checking you off your Reduction keyword fix for
dotp.c, and explain the difference in performance, if there is any. - Run your code to show the speedup.