University of California at Berkeley
College of Engineering
Department of Electrical Engineering and Computer Science
CS 61C, Summer 2010
Project 3
Due Monday, August 9, 2010 @ 11:59:59pm
TA in charge: Tom Magrino (cs61c-tc@imail.eecs.berkeley.edu)
Notes/Updates
Last Update: 2010-08-05, 6:00 pm
- There was a typo in some of the comments regarding uint_log2(), it should say that it returns 0xFFFFFFFF and not 0 for the return value if given 0.
- NOTE: there was some updates to the project files today after realizing I had messed up a few file permissions and what not. It should not affect an already working project solution, so don't panic. - Tom
- DONT FORGET you are also required to do homework 9, which I recommend doing if you're confused about how caching and virtual memory work.
- Usage of the GUI is highly recommended and will help with debugging. You only need to call the highlight_block and highlight_offset functions detailed in tips.h. append_log is also available for printing text to the GUI display. That said, we will be
- For implementation of LRU, you can assume that our tests will be running significantly fewer than billions of memory accesses, so you don't have to worry about LRU data overflow if you're doing some sort of age-based implementation.
- It is strongly recommended that you write your own .s files, and convert them to .dump for testing. The testing files we provide are grossly insufficient.
- Expect some examples of correctly working tests to go up on this page before the weekend.
- You should implement allocate-on-write; on a write miss, the appropriate block is read into the cache. This should be done regardless of write policy.
- You may assume that accessMemory will take in only word-aligned addresses.
- Remember to read tips.h for useful definitions! Particularly, all the variables in there are defined as extern and you can simply use these variables in cachelogic.c (i.e. the cache is already there for you, as well as other constants/enums).
- If you're having problems running the gui remotely due to latancy, remember that you can run TIPS locally on any instructional machine. Just remember to recompile TIPS for the machine you're running on!
- You do not have to implement any GUI functionality! It is there for your convenience only. Ignore it entirely if you want.
Contents
Brief Introduction
This project will give you intimate knowledge of cache logic through implementation of, you guessed it, cache logic. We will be providing you a MIPS simulator called TIPS (Thousands of Instructions Per Second), that will be able to run MIPS instructions. However, the cache logic is broken (read: conveniently non-existent)!
Your job is to implement the cache logic behind the cache so that TIPS can make use of the many benefits cacheing entails. You must complete this project by yourself.
Setup on (Non-Macintosh) Inst Machines
- Copy the contents of ~cs61c/proj/03 to a suitable location in your home directory.
| $ cp -r ~cs61c/proj/03/ ~/proj3 |
- To compile and run TIPS:
- As was mentioned before, the initial TIPS code has a default cache size of 0 since there is no cache logic present. You can configure the cache by clicking on the "Config Cache" button at the lower left of the interface.
Setup on Sutardja Dai Macs
Unfortunately, TIPS relies on libraries that we are not able to install on the Sutardja Dai Macs. From the macs, you will have to ssh into another server (such as nova) through the ssh -X command.
GUI Walkthrough
The GUI was designed to be straightforward. There are four main components to the GUI interface: register display, execution log, cache display, and control panel.
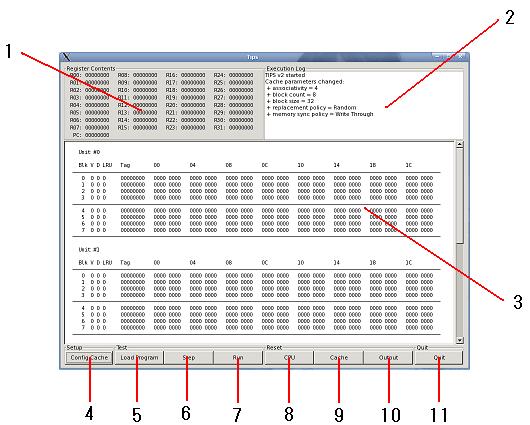 |
|
A description of each of the GUI widgets are described as follows:
- Register display -- detailed view of the current state of the registers
- Execution log -- log of actions by TIPS. Messages can be displayed in this box using the
append_log() function.
- Cache display -- current snapshot of the state of the cache. The meaning of the column headings on each unit are:
- Blk - block number
- V - valid bit
- D - dirty bit
- LRU - LRU data
- LFU - LFU data
- Tag - Tag for the block
- Numbers (00, 04, etc.) - offset in the cache block data
- Config Cache -- configure the cache parameters
- Load Program -- loads a dump file for execution
- Step -- execute one instruction
- Run -- automate execution
- CPU -- reset the PC and reinitialize registers
- Cache -- flush the cache
- Output -- clear the execution log
- Quit -- exit TIPS
|
Note: the current picture we have up is from an older version of the project, which did not include LFU, so don't worry if you're GUI looks slightly different.
There is also a text-based version of the GUI for those who prefer it (this is the version we'll be grading). You can run it with the following call:
$ ./tips -nogui
Type help at the TIPS prompt to get a list of commands usable in this mode.
Your Task
To complete this project, you must complete the accessMemory() function in cachelogic.c. This function will handle accessing actual memory, using the accessDRAM() function. Thus, the code in the accessMemory() function will behave as a cache that will call the accessDRAM() function as needed (for cache misses).
To ensure a variety of caches can be simulated, you will be required to dynamically support 5 properties:
- Associativity (ranges from 1 to 5)
- Number of unique indexes (2n where n ranges from 0 to 4)
- Block size (2n bytes where n ranges from 2 to 5)
- Replacement Policy (LRU, LFU, & Random)
- Memory Synchronization Policy (Write Back and Write Through)
More information about the variables you will be working with and the functions at your disposal can be ascertained by looking over tips.h.
You should keep the following things in mind when formulating the code:
Getting Started
Look over tips.h and cachelogic.c. tips.h gives you an overview of how the cache simulator is put together. A section of that file has been marked as important, so read it to get an idea of what functions and variables you will be using. cachelogic.c contains a slightly more detailed explanation of what you will be writing in the accessMemory() function.
The cache data structure is divided into three levels:
- The first level of entry is selecting which set you want. For example,
cache[2] states that you are going to be accessing the 3rd set of the cache. This level is regulated by set_count.
- The next level is selecting the block you want in the set. That is specified by the
block field. For example, cache[2].block[4] accesses the 5th block of the 3rd set. In the block is the tag, valid bit, dirty bit, and lru information. This level is regulated by the associativity of the cache.
- The final level of entry is selecting which bytes of the block do you want retrieve or modify. The data contained in a block is represented by the
data field of that block. Using the offset, a particular byte can be referenced.
There are two methods to access the LRU information of a block. The first method is via lru.value, a field that will hold LRU information in integer format. The other method is via lru.data, a field that will hold LRU information represented in another format (its type is void*, which means it can be a pointer to anything). You are free to use either method to represent the LRU information, so long as the LRU behaves in a deterministic fashion (i.e. no two valid blocks will ever be candidates for replacement at the same time).

Organization of the memory functions in TIPS
In a nutshell, the accessMemory() function acts as a communication layer between the CPU and DRAM. The code within accessMemory() manipulates the cache data structure defined in tips.h.
All your code MUST be contained in cachelogic.c - specifically in accessMemory() and possibly the LRU functions (depending on how you implement the LRU algorithm). You may add helper functions as long as you do not modify any code outside of cachelogic.c. Do not change any file other than cachelogic.c. Do not change the prototypes of existing functions. To summarize, you can modify only the body of the given functions, adding helper functions if needed.
Creating Dump Files for Testing
TIPS contains a subset of the MIPS R2000 processor instruction set. As a result, it accepts MIPS code assembled into binary. The dump file can be loaded into the program by clicking on the "Load Program" button.
Dump files can be created in several ways. If you are working on the inst machines, you can use the script included in the project files:
./assemble_mips input.s output.dump
Working from home is a bit trickier, but still perfectly doable. First, download Mars from here. Once you have the jar file, you have two options. If you prefer to use the GUI, go ahead and start Mars and open your assembly file. Ensure that the "Delayed Branching" setting is enabled in the Settings menu. Now, assemble the source file. Then, select the "Dump Memory" option from the File menu. Ensure that the ".text" memory segment is selected and that the dump format is Binary, and you should be good to go. If you prefer to use the command line, you can do something like this:
java -jar Mars.jar a db dump .text Binary output.dump input.s
Questions to Answer
Answer the following questions in the README file. You can safely assume that all associative caches in these questions use an LRU replacement policy.
Question 1:
For this question, assume 1KiB of addressable memory, 64B of L1 cache with 4B blocks. You will probably find it useful to draw the cache as you work through this problem.
The code in question:
#define ARRAY_SIZE 64
int total = 0;
char * array = malloc(ARRAY_SIZE * sizeof(char)); /* Line 1 */ // Note: chars are 1-byte wide
for(int x = 0; x < ARRAY_SIZE; x++) array[x] = x; /* Line 2 */
for(int x = 0; x < ARRAY_SIZE; x++) total += array[x]; /* Line 3 */
for(int x = 0; x < ARRAY_SIZE; x++) total += array[x]; /* Line 4 */
a. Assume the cache is direct-mapped and array is a pointer to the memory at offset 0b1001111000, what is the ratio of cache hits to cache misses while Line 4 is being executed?
b. Assume the cache is fully associative and array is a pointer to the memory at offset 0b1001111000, what is the ratio of cache hits to cache misses while Line 4 is being executed?
c. Assume the cache is direct-mapped and array is a pointer to the memory at offset 0b1001111101, what is the ratio of cache hits to cache misses while Line 4 is being executed?
d. Assume the cache is fully associative and array is a pointer to the memory at offset 0b1001111101, what is the ratio of cache hits to cache misses while Line 4 is being executed?
e. Do these results surprise you? Why or why not? Explain what's going on. What would happen if the cache were 2-way set associative? 4-way?
Question 2:
Explain the differences between write-through and write-back caches, and when/why one might be preferred over the other.
Question 3:
Describe a situation in which a 2-way set associative cache would out-perform a fully associative cache. Vice-versa? You should describe these situations in relation to the attributes of the cache. (i.e. accesses are made to fill every block of the cache, hitting memory block-size apart each time...) Otherwise, the examples can be as contrived as you wish.
Question 4:
Briefly describe the changes you would have to make to your implementations in this project to implement an L2 cache. Assume you're given a second cache struct. How would your L1 cache implementation change? How, if at all, would your L2 cache implementation need to be different from your original cache implementation? YOU ARE NOT EXPECTED TO IMPLEMENT THIS.
Question 5:
Suppose for a moment that virtual memory was included in this project. How would you expect the input to accessMemory() to change? (in other words, what type of information should the cache now receive in order to do its thing?) YOU ARE NOT EXPECTED TO IMPLEMENT THIS.
Submitting Your Solution
Repeated for emphasis: All your code MUST be contained in cachelogic.c (this is the only code you submit).
In testing your project, we will use all of our own files (including the Makefile) EXCEPT for your submitted cachelogic.c.
A README file should be submitted with your answers to the questions above and anything the grader should know reader about your project.
Bugs and Suggestions
If you think you have found a bug in the TIPS GUI/code, please let the staff (i.e. the TA in charge) know via email or the newsgroup. Likewise, feel free to let us know of any suggestions you have. Bugs and suggestions will be addressed in updated files for this project if necessary.
Frequently Asked Questions
Q: What are the definitions of associativity and set?
A: Associativity is the number of cache block locations where a given memory block can be placed using the memory block's index.
Set is the collection of blocks associated with the SAME index. The number of unique indexes in the cache is equal to the number of sets you have.
Q: I am updating the cache in my function, but the GUI isn't doing anything. What is going on?
A: The GUI needs to be informed when changes are made to the cache. The GUI functions at your disposal are mentioned in tips.h.
Q: How much of the GUI behavior do I have to copy?
A: You will only be graded on your implementation of the cache logic in cachelogic.c. You do not have to include the GUI update function calls if you don't want to, but they will help you visually understand how caching works.
Q: Should I follow the LRU algorithm seen in P&H?
A: No, you should not follow the LRU algorithm in P&H. The LRU algorithm in P&H is an approximation LRU algorithm, which produces ties between valid blocks that are candidates for replacement. As a result, it is suggested you should use a true LRU algorithm, where there is a unique ranking between valid blocks. In other words, there should never be any randomness in your LRU replacement policy, nor should it always default to kicking just one block out in the event of a "tie" (two LRU values being the same for two valid blocks -- blocks with valid bit set to 1).
Q: Do I have to use numbers for my LRU algorithm?
A: No, you do not have to use numbers for your LRU algorithm. If you want to use something else (such as time structs), use lru.data as the pointer to this data. Make sure you update the init_lru() function and the lru_to_string() function.
Q: Are the addresses in this project byte addressed or word addressed?
A: They are byte addressed.
Q: What do you mean by unit of transfer between cache and physical memory is in blocks?
A: This means if you have blocks in your cache with a size of 4 words, you must always move data to and from physical memory in units of 4 words. There should never be a time in which the amount of data you move to physical memory from cache be less or greater than the block size of the cache.
Q: Can I add more files to the project?
A: You can, but we will not be able to test your solution in the autograder. We will ignore all files you submit except for cachelogic.c (and the README, of course). Do NOT put any code needed by your cachelogic.c (including header files and such) in any external file. If that's not clear, edit only cachelogic.c please -- your grade will appreciate not being a 0.
Q: Can I work from home without the GUI?
A: Yes, there is a "No GUI" mode for TIPS that can be activated by adding the -nogui flag on the command line when starting TIPS. For instructions, type "help" on the prompt after starting up TIPS.
Q: Can I work from home without using SSH?
A: Yes, the Makefile in the proj3 folder will allow compilation on Cygwin/Windows, OS X, and Linux automatically.
Q: Can I start TIPS with a dump file already loaded?
A: Yes, TIPS will interpret the last argument on the command line as a name of a file. If you want to start up TIPS with a dump file named test23.dump, you can type the following:
% ./tips test23.dump
Q: I typed in make and it says there is an error in the Makefile. What's wrong?
A: Use gmake. Note that you make not already have this installed on your machine (see setup instructions below).
Q: I ran gmake and I can't compile this project on Cygwin/Windows because of *some reason*. What do I have to do to get it to compile on Cygwin/Windows?
A: This project's GUI interface is built on GTK+. Compiling this project on Cygwin/Windows requires you at least install the packages mentioned in "Setup on Windows Machines (Cygwin)." Information about specifics of the general GTK+ installation can be found here.
Q: Can I use other compilers on Windows?
A: All the project files are configured for use on Sparc/Solaris or Cygwin/Windows. If you want to use other compilers (i.e. Microsoft Visual Studio), you will have to find the libraries usable with those compilers and make the appropriate modifications. Remember, you must make sure your program compiles on the standard instructional computers (details of which server exactly will be released later).
Setup on Windows Machines (Cygwin)
- If you have a Cygwin install already, make sure to run setup.exe again and verify that the required packages below are installed.
- Download http://www.cygwin.com/setup.exe and run setup.exe. If you've already installed Cygwin, it is perfectly safe to rerun the setup to download additional packages for this project.
- Accept all the defaults and pick a mirror, i.e. ftp://mirrors.dotsrc.org, and select the following packages in the following <<Categories>>
<<X11>>
xorg-x11-devel
xterm
<<Devel>>
gcc
gdb
gtk2-x11-devel
make
pango-devel
pkg-config
|
<<Editors>>
vim (or emacs, if you like your text editor to be an operating system)
<<GNOME>>
atk-devel
<<Net>>
openssh
<<Games>>
Just kidding =P
|
- Selecting these packages will automatically select other packages required -- Do NOT uncheck these!
- Finish setup, run Cygwin Bash Shell once to make sure it works.
- Manually make a shortcut to Cygwin with X by browsing to C:\Cygwin\usr\X11R6\bin and dragging and dropping startxwin.bat with the right click button to your desktop.
- Download ttf-bitstream-vera-1.10.tar.gz and put it in C:\Cygwin\home\your_user_name
- Run startxwin.bat (from that shortcut) and type the following:
| $ mkdir /usr/share/fonts |
| $ cd /usr/share/fonts |
| $ tar xvzf ~/ttf-bitstream-vera-1.10.tar.gz |
- Should startxwin.bat not work (if you have any difficulties running Cygwin, starting multiple xterms, resource unavailable and fork() fails - specifically on Vista), Start>Run and run "cmd". Make sure that before you run this command, quit ALL Cygwin windows and processes (Ctrl+Shift+Esc, kill Xwin.exe, and others). Then in the command prompt:
| C:\Users\You>C:\Cygwin\bin\ash |
| $ /bin/rebaseall |
- Get Project 3 stuff, where XX below is your login:
| $ scp -r cs61c-XX@nova.cs.berkeley.edu:/home/ff/cs61c/proj/03/ ~/proj3 |
| $ cd ~/proj3 |
| $ make |
| $ ./tips |
- Note that in Cygwin, you use make, not gmake.
Setup on OS X
Leopard users: Go download XCode 3.0 from Apple's site. You'll have to register as a developer, but accounts are free. After downloading the 1.1GB XCode dmg, open it and install XCode. Then, continue with installing MacPorts below.
Non-Leopard users (10.4 and before): Go download XCode 2.5 from Apple's site. Again, you may have to register as a developer. Then, download the X11 package and install it, then continue with installing MacPorts below.
Next, install MacPorts (instructions are on their site), and enter these commands in Terminal:
$ sudo port install gmake
$ sudo port install gtk2 |
You should be good to go!
Setup on Linux
If you've made it this far in the semester with Linux, you should have the necessary compilers and libraries needed to compile the project. However, to ensure that you have the correct GUI libraries, you might need to install a few new packages.
If you are using a Debian based distribution (like Ubuntu):
| $ sudo aptitude update && sudo aptitude install build-essential libgtk2.0-dev |
If you're still getting errors, you may need to install another package. Look at the output of "uname -a" and look for a string like "Linux 2.6.15-28-686". Take note of the bolded numbers (your arch) and do:
| $ sudo aptitude install linux-headers-arch |
If you're on a different distribution, look in your package management system for the appropriate packages.