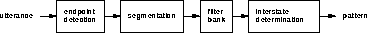
Figure 1: Content-free high level block diagram.
EECS20: Introduction to Real-Time Digital Systems
Lab10: Digit Recognition
EECS20: Introduction to Real-Time Digital Systems
©1996 Regents of the University of California.
By K. H. Chiang, William T. Huang, Brian L. Evans.
URL: http://www-inst.eecs.berkeley.edu/~ee20
News: ucb.class.ee20
Voice recognition systems can be categorized according to three criteria:
In this lab, we will implement a speaker dependent, small vocabulary, isolated-word recognizer. Specifically, we will attempt to recognize the digits from 0 through 9.
We follow the approach outlined in Figure 1:
Figure 1: Content-free high level block diagram.
This still leaves us with the problems of how to generate patterns, and how to make the comparisons between the patterns. We first address the former.
The pattern generation can be broken down into four major steps, as illustrated in Figure 2: endpoint detection, segmentation, filtering, and interstate determination.
wavread command. In
addition, after reading the sample into Matlab, don't forget to subtract 128
from the entire speech sample to normalize the speech around 0.
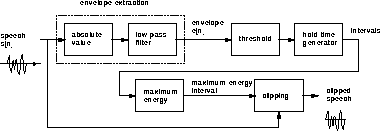
Endpoint detection is accomplished by the process illustrated in Figure 3.
The classic endpoint detector performs a number of operations:
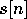 is found by taking the
absolute value of and then low pass filtering through a first order
LPF. This gives
is found by taking the
absolute value of and then low pass filtering through a first order
LPF. This gives 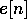 .
A suggested transfer function for the LPF is:
.
A suggested transfer function for the LPF is: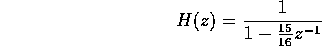
Following the notation of the filter command, the b vector is
[1] and the a vector is [1 -15/16].
is then passed through a threshold detector. This
gives the values of  for which is greater than some threshold value.
This threshold value should be determined by recording a speech sample and a
sample of background noise, and then finding some value greater than the noise
sample's envelope and less than the speech sample's envelope.
for which is greater than some threshold value.
This threshold value should be determined by recording a speech sample and a
sample of background noise, and then finding some value greater than the noise
sample's envelope and less than the speech sample's envelope.
that correspond to greater than the threshold value
have been found, a hold time generator takes those values of and throws out
all the that are within some number of samples of each other. A value of
1000 is suggested for this hold time; if the sample rate 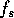 was 8 kHz, this
would correspond to 125 ms.
was 8 kHz, this
would correspond to 125 ms.
Starting from the beginning of the list of values of and throwing out
points will give the starting points of any intervals possibly containing
speech, whereas starting from the end of the list of values of
will give the ending points of any such intervals.
One of the problems in speech recognition is that the same word may be pronounced at different speeds. For instance, a person could say a given digit very quickly or very slowly, but we would still like to recognize that digit.
To deal with this, after removing the zeros at the beginning and end of an
utterance, we segment the speech into sixteen separate, nonoverlapping
segments. This is easily done in Matlab with proper indexing. We hope that
even though a digit can be spoken at different speeds, the th segment of a
slowly spoken digit contains the same information as the th segment of a
quickly spoken digit.
Each of the sixteen segments is then filtered with a bank of 19 filters.
The coefficients for the filters are provided for your filtering pleasure.
Loading the filter bank is accomplished by the command load filtbank,
assuming that the file filtbank.mat is in the current working directory.
This loads the matrix abank and the matrix bbank. Each row of
abank contains the a vector of a DT filter, and each row of
bbank contains the b vector of a DT filter, following the naming
convention of the filter command.
The magnitude responses of the filters are given in Figure 4.
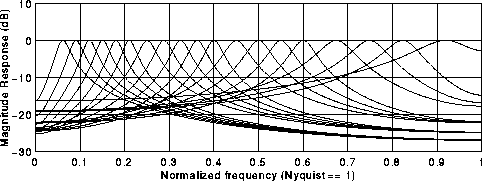
Figure 4: Filter bank magnitude response.
Another problem in speech recognition is amplitude normalization; a person can say the same word with the emphasis on different syllables, or at a completely different overall volume. To remedy this, we use a technique termed ``interstate determination.''
After filtering, we have 19 vectors of filter outputs for each of the sixteen segments. To get that data down to a more reasonable size, we determine the energy in each of the filter outputs by taking the sum of the squares of the samples. We then compare the energy of the second filter with the first. If the energy of the second filter is greater than the first, we represent this as a 1. Otherwise, it's a 0. We repeat this pairwise comparison for the third and second filter output energies, and so on.
So, after the endpoint detection, segmentation, filtering, and interstate determination, we end up with 18 ones and zeros in a given segment. With sixteen segments, we then have 288 numbers in the pattern for a given utterance.
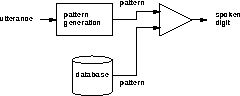
If three samples are recorded for each digit and the corresponding patterns are generated, we would have thirty patterns in a database of reference digits.
Now, we can use the database by recording a new sample, generating its pattern, and comparing this pattern to each of the candidate patterns in the database. The comparison can be performed by counting the number of ones and zeros which do not match. We hope that the digit whose pattern is the closest match is the spoken digit, closest match being defined as the lowest number of mismatched ones and zeros.
SoundOLE application in the
Audio group for recording.