61Ccc Code Generation
Deadline: Friday, March 1st
Getting started
Please accept the github classroom assignment by clicking this link. Once you’ve created your repository, you’ll need to clone it to your instructional account and (if you choose) your local machine. You’ll also need to add the starter code remote with this command:
git remote add staff https://github.com/61c-teach/sp19-proj2-starter
If we publish changes to the starter code, you may get them by running git pull staff master
Please read the entire spec before beginning the project.
What is Code Generation?
This project will finish off the compiler you started to build in Project 1. Recall a compiler contains the following components, each processing INPUT and creating OUTPUT.
| SECTION | INPUT | OUTPUT | NOTE |
| Lexer (Proj 1-1) | sample.61c | Tokens List | The lexer will error if you use symbols that are not supported by the language you’re compiling. |
| Parser (Proj 1-2) | Tokens List | AST | The parser will error if the tokens are in the wrong order (or if we’re missing tokens). |
| Type Checking and Scoping (Decorating) | AST | Decorated AST (DAST) | The DAST contains additional information about the declarations and types used by each node. You shouldn’t need to worry about this code or the structures it works with. All you need to understand is that this phase catches type and scope related errors and generated the structure that the code generator reads to produce the assembly. |
| Code Generation (Proj 2) | DAST | sample.s | ??? |
Code generation is the last step of our compiler. It takes in a DAST and produces RISC-V assembly code which, when executed in Venus, performs the actions described in our original 61C file. You do not need to worry about producing errors, though generally the code-generation component is where you get errors like “Invalid operation: division by zero” among other things that can only be checked at runtime.
For this project, you’ll be writing C code that produces RISC-V code. This can be tricky, but we know you can do it! We’d like to emphasise that this project isn’t meant to test your C-coding abilities; we won’t be running any memory checks and we aren’t concerned with Valgrind errors (though if something doesn’t work, they’re a good debugging first-step!).
To help you get into the project faster, we’ve added two new sections to the spec “Reading the Code” which will (hopefully) connect some dots around what the existing code structure does and “Function Descriptions” which outlines the parts of the codebase you’re expected to change and what changes you should make.
Happy coding!
Reading the Code
In Project 1, we received feedback that it was hard to tell how different functions related to one another. In this section, we’ll try to head off this confusion :)
Before we start, open cgen.c and main.c and try to follow along. If you’re in Sublime, you can use CMND + R (CTRL + R on Windows probably?) to search for method names and jump to their definitions. Try to view the code as we describe it.
Let’s start with main.c. Remember how we ran our tests with ‘-p’ for parsing and ‘-t’ for tokenizing? We’ve added a ‘c’ flag indicating we’d like to generate assembly code for the given file. Note that by the time we reach the conditional checking this flag, we’ve already done the lexing, parsing, and decorating required to generate the DAST (code generation’s input structure). We then pass the DAST into a function called GenerateCode which is the boilerplate method for our code generator.
Switch over to cgen.c and find GenerateCode. This function does three things. First, it creates all necessary global data (variables declared globally and all strings used in the file) and places it in the .data section of our outputted assembly file. Then, it calls dispatch to generate assembly for the DAST starting with the root that was passed in. Lastly it does some memory management and free’s a structure we allocate to manage our global data.
Let’s focus for now on the dispatch call. The dispatch function takes in a DAST and decides how to generate assembly code based on its type. These types are the same ones you worked with in Proj 1-2 and you can find them in the ast.h file.
Based on the type of the node, the appropriate process function is called. Not all nodes require processing (ie. there are some nodes in our DAST that are helpful in parsing or decorating but don’t have formal meaning in code generation; NODETYPE_EXPR_CAST is one such example) so we have a default case which does nothing for the current node, but tries to dispatch recursively on its children.
Within the selected process function, assembly instructions are emitted to our output file. Each process function emits assembly only for the node it processes (eg. the processBlock function sets up stack space for the block’s elements but leaves their actual storage to the process function that is recursively called through dispatch).
Let’s take a look at one process function in more detail. Below is the code for processExprPrefixNegate; this is called when we’re dispatching on a node that contains a negation expression (ie. -4).
Before analysing the function, we should look up the negation node in the parsing table to see how many children it has and how they’re ordered.
| Name | Node type | # Children | Children |
| Negate | NODETYPE_EXPR_PREFIX_NEGATE | 1 | 0: Expr |
We can see it has one child, an expression (4 in our previous example). If we want to produce -4 as our final result, we’ll first need to evaluate the expression which returns 4 and then negate it, or multiply by -1.
The dispatch call on child is how we generate the value 4. By our code generation invariants, we know the value (whatever it is) is now in register S1.
The next thing to do is multiply by -1. First we load the immediate (-1) into a temporary register with an ADDI. Then we multiply and store back to S1 the final value -4.
void processExprPrefixNegate(DAST* dast, char* startLabel, char* endLabel) {
DAST* child = dast->children[0];
// cgen and load arguments
dispatch(child, startLabel, endLabel);
// negate
emitADDI(T0, x0, -1);
emitMUL(S1, S1, T0);
}
Open up instructions.c and note how we generate assembly. Each time we want to write an assembly instruction, we call emitINST where INST is the instruction we’d like to send to our output file. The ordering of arguments to emit functions is extremely important. Because registers are enum types, if you accidentally switch the ordering of a register and immediate, the C compiler won’t error.
You are welcome to add more instruction functions if you like, though you may want to look at your green sheet to figure out instruction formatting. If your code does not execute in Venus, it will not execute in the staff autograder. Test thoroughly!
You may not alter the registers you’ve been given (though you don’t have to use them all in your code!)
This project relies upon modularising your code and an understanding of recursion/call structure. If you need more clarification on exactly what each function is meant to do (and what it should leave to other functions to accomplish) don’t hesitate to post on piazza. We’d rather address misconceptions early than have you rewrite large chunks of code last minute.
Code Generator Invariants
In addition to the functions/call structure we described above, there are a few more design points to be made before you begin coding.
First: every time an expression is evaluated in assembly, the result must be saved in register S1. You can see a basic example of this in the processConstInt function and a more complex example in the processExprPrefixNegate function above. DO NOT BREAK THIS INVARIANT. You should not use register S1 for anything other than passing/receiving intermediate values from expressions.
The only exception to this rule is the return statement which saves its value in A0 to abide by RISC-V convention.
Because we assume S1 holds the value of nearly every expression after processing, you’ll find yourself having to use the stack to save intermediate values frequently. This is expected. Look at the pseudocode for a binary add expression below:
child1 = dast->children[0]; // left expression
child2 = dast->children[1]; // right expression
dispatch(child1);
/* our left expr result is now in S1! but... if we call dispatch on child2,
* we'll overwrite the value from child1... */
emit??? // make room on the stack/move pointer
emit??? // save value to stack
/* yay! S1 is free to use */
dispatch(child2); // S1 holds right expr result
emit??? // load left expr result from stack
emit??? // add values and place result in S1 to keep invariant true
emit??? // erase value from stack/restore pointer
In addition to the S1 invariant, we will introduce a few other deviations from the general Callee/Caller convention you’re used to. First, we do not use argument registers (a0, a1, …) to pass arguments to functions. Instead we push all arguments onto the stack (We will still use a0 to save our return value!). Second, we will make use of the frame pointer in addition to the stack pointer.
The frame pointer is changed at the beginning of a function’s invocation. It marks the end of the function arguments (stored above) and beginning of the function’s local variables (stored below). We cannot simply rely upon the stack pointer because the stack will change sizes as the function executes; we use the frame pointer so that our function arguments are always at a constant offset from a fixed point. The image below demonstrates how arguments are loaded onto the stack and where the stack pointer and frame pointer point before, during, and after a function call.
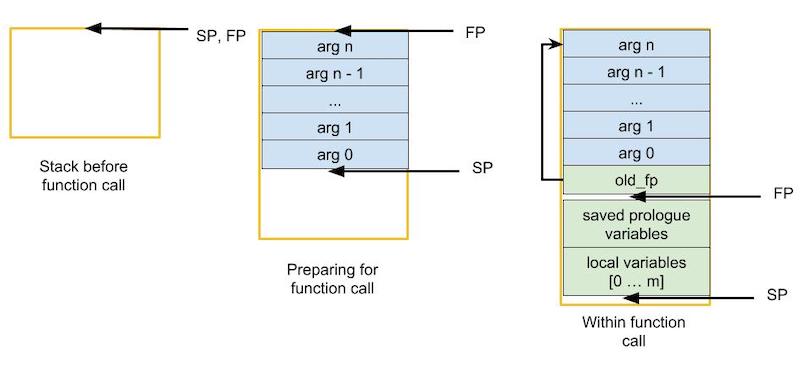
Apart from the three changes to convention listed above, we will follow RISC-V convention as you’ve learned in class. This means saved registers should be put onto the stack when used and restored after. Likewise temporaries are not assumed to persist across function calls. Since we have not defined behaviour for argument registers, you are free to impose your own convention.
NOTE: We will not be visually inspecting your code to ensure it abides by convention, though it is in your best interest to do so as it makes managing registers much easier. You can expect the final autograder to stress test your code generator by providing many arguments and lots of stack manipulation.
Function Descriptions
Similar to the “Reading the Code” section, we want to make sure you have enough information to understand the objectives of each function you’re writing. Below is a list of functions you must modify in order to complete the project. You may modify other functions aside from these, however it is possible to attain a full score modifying only this list. You are also welcome to add additional helper functions if needed.
The only function you may not change is the header for GenerateCode since this is called from main.c within the autograder. If you modify this your solution will not run.
The first set of functions you’ll work with are those that generate code for binary expressions.
Each of the functions takes in a DAST with two direct children: the left-hand expression before the operator and the right-hand expression after the operator (Remember the parsing table? You may find it helpful for this section). These expressions may be constants, or other unary/binary expressions (ie. they may have children themselves). The following table gives you more information about what types each operation is defined on.
You should dispatch on each of the child expressions before performing the given operation and returning the final value in register S1. You should use the stack to store intermediate values. The type information given below is for your knowledge only; if you call the correct function you will not have to explicitly check the type of the DAST.
| Bianry Function(s) | Valid when applied to... |
| `processExprBinaryAdd` `processExprBinarySub` `processExprBinaryMul` `processExprBinaryDiv` | Addition and subtraction are defined on int/int, char/char, and pointer/int or int/pointer children. Subtraction is also defined on pointer/pointer. Multiplication and division are both defined on int/int and char/char. |
| `processExprBinaryEq` `processExprBinaryNotEq` | Equality and inequality are defined on two objects of the same type. The type can be any of the ones our language supports (int, bool, char, string, pointer, struct, struct fields). |
| `processExprBinaryGTEq` `processExprBinaryGT` `processExprBinaryLTEq` `processExprBinaryLT` | Less-than, less-than-or-equal, greater-than, and greater-than-or-equal are all defined on int/int, int/char, char/int, or pointer/pointer arguments. |
| `processExprBinaryLogicAnd` `processExprBinaryLogicOr` | Our logical operators are defined on booleans, integers, characters, struct fields, strings, and pointers. In short, they’re defined on everything but struct instances |
| `processExprBinaryBitAnd` `processExprBinaryBitOr` `processExprBinaryBitXor` | Our bitwise operators are defined on int/int and char/char arguments. They work on a bitwise level and assume immediates are signed. |
The second set of functions you’ll work with are function declarations (processFuncDecl), call expressions (processExprCall), and if/else statements (processIfElse).
You should only generate code for function declarations that have a body (this check is done for you). You’ll need to save and move the frame pointer, generate the appropriate prologue/epilogue based on calling conventions, and recursively generate code for the function body. Be sure to return the stack to its original state before exiting.
Call expressions should copy the given arguments to the stack (if there are arguments to copy) in descending order. Start with the last argument in the arguments list and progress backwards towards argument zero. Then, jump to the function, pass up the return value, and return the stack to its original state before exiting.
If/Else statements require some additional processing; not every one has both an if and else body. In the case of just an if, generate the condition, check it, and jump to the body or the end of the block. If you have an if and an else case, do the if processing, but instead of jumping to the end, jump to the start of the else block. Remember you should only execute either the if or the else but not both. This requires labels! Take a look at the functions in cgen-helpers.c for label generating functions.
Your Tasks
Task One: Binary Expressions
Modify the binary expression functions in the table above such that they generate proper assembly code. We recommend you start with the pseduocode ADD example above and work your way through the arithmetic instructions before moving to comparative ones.
Generally, these expressions should be very similar in form. They also should be rather short. Don’t over-complicate things!
You are welcome to write test files for binary expressions, but keep in mind you won’t be able to completely run them in Venus until you’ve implemented function declarations. This is because our language doesn’t allow non-constant expressions at the global level (ie. everything has to be in a function). If you write test files and cgen them your code will still generate, but you’ll get some extra/incomplete function headers. You’re welcome to write tests and inspect them visually or copy the relevant portions to Venus for individual testing :) See the testing appendix for more information on printing variables and Venus debugging.
Task Two: Function Declarations
There are three things you’ll need to do to get functions working properly; first, save the old frame pointer and set the new value according to our image above. Second, set up the prologue and epilogue at the comments provided in processFuncDecl. You should assume all registers that require saving will be used. If you are treating argument registers as saved registers, remember to include them! Once you’ve set up the prologue and epilogue, decide how we should trigger code generation for our function body. Again, try to keep it simple. This is not meant to trick you!
After implementing this, you should be able to test binary expressions by running the assembled code directly in Venus. You will be able to run code /inside/ a function, but you have not implemented call expressions, so you won’t be able to call functions directly. See the testing appendix for more information on printing variables and Venus debugging.
Task Three: Call Expressions
Now that we have functions to call, let’s work on calling them by modifying processExprCall. When a function is called with a call expression, its arguments should be saved on the stack in descending order (ie. the last argument should be saved first, then the second to last, etc.) Review the image above showing frame-pointer use for clarification.
After the arguments are saved, you should call the function.
Next, move the return value to maintain our code generator invariant.
Lastly, remove the arguments and restore the stack.
Once you’ve completed this section you’ll be able to call and return from functions (that do not contain if/else statements). You can write tests for this functionality and run them directly in Venus. In the next section we’ll implement if/else statements and finish the generator!
Task Four: If/Else Statements
The last part of your project requires implementing support for if/else statements. First, handle the case that there is only an if condition (ie. no else body). Generate the appropriate label(s), check the condition, and generate the body.
Next, add support for the else case. Be sure to execute either the if body or the else body but not both. You can do this with a branch-jump pair and additional label(s).
Once you’ve completed this section all code that can be parsed should be able to be generated and run in Venus.
Congrats! You’ve finished the project! :)
Appendix
Testing
Like previous projects, we expect you to write your own tests to check your program’s functionality. At the end of each task above, we’ve described what you’ll be able to test, in this section we’ll talk about how you should test it. You can test the file sample.61c as follows:
make clean
make
./61Ccc -c tests/cgen/sample-tests/sample.61c
This will output to standard out the assembly code generated by your code generator. If you’d like to send this to a separate file, you may do so as follows:
./61Ccc -c tests/cgen/sample-tests/sample.61c > myfile.txt
You can also copy the output directly to your clipboard with the following on Mac OS:
./61Ccc -c tests/cgen/sample-tests/sample.61c > pbcopy
Once you’ve gotten your generated assembly, you can test its validity by running it in the Venus simulator. Paste it into the editor tab and click “simulator”. You can run or step through the program as described in lab. Click a line to set a breakpoint, or type ebreak into the editor to force a breakpoint at a particular line. Use the interface at right to view current register values (remember you can change the viewing settings to hex or decimal).
If you prefer to test locally, we’ve also provided a .jar of Venus.
Our language does not have a print function by default meaning your functions won’t output to Venus’s standard-out. To help you verify your code, we’ve included a few specialised print functions in cgen-lib/print.h. You can insert these into your 61C code and, when assembled, Venus will print your values. See tests/cgen/sample-tests/print-sample.61c for a use case.
NOTE: We do not recommend using these functions while debugging assembly in Venus because they insert additional function calls and make it difficult to separate the code you’ve written from the code being generated. They should be used for quick verification and removed to narrow down larger issues.
Autograding
We will be providing an autograder for this project. It will provide about 50% coverage for your code generator and you will have unlimited submission attempts. The score you receive on the autograder will not determine your score on the project overall. We highly suggest you write your own test cases. A few test-case suggestions (this is not an exhaustive list, its just what Morgan thinks you should start with):
- Functions with no arguments
- Functions with arguments that are a mix of strings, integers, pointers, etc.
- Functions with many (many) arguments
- Functions with expressions as arguments
- Nested binary expressions
- Call expressions with the argument combinations above
- Multiple recursive calls with return values
- Functions that use/modify local variables
- …
We will be releasing a grading breakdown closer to the project deadline, check out piazza for details.