Lab 7: Parallelism I - SIMD, OpenMP
Deadline: Monday, April 10, 11:59:59 PM PT
Setup
You must complete this lab on the hive machines (not your local machine). See Lab 0 if you need to set up the hive machines again.
In your labs directory on the hive machine, pull any changes you may have made in past labs:
Still in your labs directory on the hive machine, pull the files for this lab with:
If you run into any git errors, please check out the common errors page.
Overview
In this course, we cover three main types of parallelism:
- Data level parallelism (SIMD)
- Thread level parallelism (OpenMP)
- Process level parallelism (Open MPI)
This lab will cover DLP as well as some of TLP, while the next lab will cover the rest of TLP as well as PLP.
SIMD
Read over the Intel Intrinsics Guide to learn about the available SIMD instructions (an intrinsic function is a function whose implementation is handled by the compiler). The Intrinsics Naming and Usage documentation will be helpful in understanding the documentation.
The hive machines support SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, and AVX2, so you can check those boxes in the filters list. Some of the other instruction sets are also supported, but we can ignore those for the purposes of this lab.
While there's no deliverable for this section, reading the documentation will be extremely useful for other exercises in this lab and for project 4.
Example: Loop Unrolling
The sum() function in ex1.c is an un-optimized implementation of the sum the elements whose value is >= 128 of a really big array (roughly 2^16 elements). We use an outer loop to repeat the sum OUTER_ITERATIONS (roughly 2^14) times to increase the code runtime so we can take decent speedup measurements. We time the execution of the code by finding the difference between the start and end timestamps (using clock()). The file ex1_test.c is the one which will have a main function to run the various sum functions.
Let's look at sum_unrolled(). The inner loop processes 4 elements per iteration, whereas the inner loop in sum() processes 1 element per iteration. Note the extra loop after the primary loop -- since the primary loop advances through the array in groups of 4 elements, we need a tail case loop to handle arrays with lengths that are not multiples of 4.
For this lab, we've provided Makefiles, so please use the provided make commands instead of gcc to compile your code. Try compiling and running the code:
The unrolled function should be slightly faster, although not by much. But faster programs are always nice to have!
Question: if loop unrolling helps, why don't we unroll everything?
- The unrolled code is harder to read and write. Unless you plan to never look at the code again, code readability may outweigh the benefits of loop unrolling!
- Sometimes, the compiler will automatically unroll your naive loops for you! Emphasis on sometimes -- it can be difficult to figure out what magic tricks a modern compiler performs (see Godbolt in the next paragraph). For demonstration purposes, we've disabled compiler optimizations in this lab.
- Loop unrolling means more instructions, which means larger programs and potentially worse caching behavior!
- Our simplified examples in
ex1.cuse a known array size. If you don't know the size of the array you're working on, your unrolled loop might not be a good fit for the array!
Optional: you can visualize how the vectors and the different functions work together by inputting your code into the code environment at this link!
Another interesting tool that might help you understand the behavior of SIMD instructions is the Godbolt Compiler Explorer project. It can also provide a lot of insights when you need to optimize any code in the future.
Exercise 1: Writing SIMD Code
The following code demonstrates how to add together an 8-element integer array using SIMD instructions. Our registers in this example are 128-bits and integers are 32 bits. This means that we can fit four integers into one register.
int arr = ;
// Initialize sum vector to {0, 0, 0, 0}
__m128i sum_vec = ;
// Load array elements 0-3 into a temporary vector register
__m128i tmp = ;
// Add to existing sum vector
sum_vec = ;
// sum_vec = {3, 1, 4, 1}
// Load array elements 4-7 into a temporary vector register
tmp = ;
// Add to existing sum vector
sum_vec = ;
// sum_vec = {3 + 5, 1 + 9, 4 + 2, 1 + 6}
// Create temporary array to hold values from sum_vec
// We must store the vector into an array in order to access the individual values (as seen below)
int tmp_arr;
;
// Collect values from sum_vec in a single integer
int sum = tmp_arr + tmp_arr + tmp_arr + tmp_arr;
This is a lot of work for adding together 8 elements. However, this process greatly improves the performance of summing together the elements of large arrays.
-
Implement
sum_simd(), a vectorized version of the naivesum()implementation. -
Copy your
sum_simd()code intosum_simd_unrolled()and unroll it 4 times. Don't forget about your tail case!
Tips
-
You only need to vectorize the inner loop with SIMD. Implementation can be done with the following intrinsics:
__m128i _mm_setzero_si128()- returns a 128-bit zero vector__m128i _mm_loadu_si128(__m128i *p)- returns 128-bit vector stored at pointer p__m128i _mm_add_epi32(__m128i a, __m128i b)- returns vector (a_0 + b_0, a_1 + b_1, a_2 + b_2, a_3 + b_3)void _mm_storeu_si128(__m128i *p, __m128i a)- stores 128-bit vector a into pointer p__m128i _mm_cmpgt_epi32(__m128i a, __m128i b)- returns the vector (a_i > b_i ?0xffffffff : 0x0forifrom 0 to 3). AKA a 32-bit all-1s mask if a_i > b_i and a 32-bit all-0s mask otherwise__m128i _mm_and_si128(__m128i a, __m128i b)- returns vector (a_0 & b_0, a_1 & b_1, a_2 & b_2, a_3 & b_3), where & represents the bit-wise and operator
-
DON'T use the store function (
_mm_storeu_si128) until after completing the inner loop! It turns out that storing is very costly and performing a store in every iteration will actually cause your code to slow down. However, if you wait until after the outer loop completes you may have overflow issues. -
Read the function declarations in the above table carefully! You'll notice that the loadu and storeu take
__m128i*type arguments. You can just cast an int array to a__m128ipointer.
Testing
To compile and run your code, run the following commands (reminder: please use make, not gcc):
The naive version runs at about 7 seconds on the hive machines, and your SIMDized version should run in about 1-2 seconds. The unrolled SIMDized version is slightly faster than sum_simd, but most likely by just a few fractions of a second.
The autograder tests are similar to those in ex1_test.c, but with potentially different constants (NUM_ELEMS and OUTER_ITERATIONS) and reduced speedup requirements (to compensate for more variability in autograder resources).
Common Bugs
Below are common bugs that the staff have noticed in implementations for this exercise.
- Forgetting the conditional in the tail case: what condition have we been checking before adding something to the sum?
- Adding to an uninitialized array: if you add stuff to your result array without initializing it, you are adding stuff to garbage, which makes the array still garbage!
- Re-initializing your sum vector: make sure you are not creating a new sum vector for every iteration of the inner loop!
- Trying to store your sum vector into a
long long intarray: use an int array. The return value of this function is indeed along long int, but that's because anintisn't big enough to hold the sum of all the values across all iterations of the outer loop.long long intandinthave different bit widths, so storing anintarray into along long intwill produce different numbers!
General SIMD Advice
Some general advice on working with SIMD instructions:
- Be cautious of memory alignment. For example,
_m256d _mm256_load_pd (double const * mem_addr)would not work with unaligned data -- you would need_m256d _mm256_loadu_pd. Meanwhile, if you have control over memory allocation, is almost always desireable to keep your data aligned (can be achieved using special memory allocation APIs). Aligned loads can be folded into other operations as a memory operand which reduces code size and throughput slightly. Modern CPUs have very good support for unaligned loads, but there's still a significant performance hit when a load crosses a cache-line boundary. - Recall various CPU pipeline hazards you have learned earlier this semester. Data hazards can drastically hurt performance. That being said, you may want to check data dependencies in adjacent SIMD operations if not getting the desired performance.
OpenMP
OpenMP stands for Open specification for Multi-Processing. It is a framework that offers a C interface. It is not a built-in part of the C language -- most OpenMP features are compiler directives. (One example of a compiler directive you've seen in the past is #include.)
Benefits of multi-threaded programming using OpenMP include:
- A very simple interface that allows a programmer to separate a program into serial regions and parallel regions.
- Convenient synchronization control (data race bugs in threads are very hard to trace).
Example: OpenMP Hello World
Consider the sample hello world program (openmp_example.c), which prints "hello world from thread #" from each thread:
int
This program will create a team of parallel threads. Each thread prints out a hello world message, along with its own thread number.
Let's break down the #pragma omp parallel line:
#pragmatells the compiler that the rest of the line is a directive.ompdeclares that the directive is for OpenMP.parallelsays that the following block statement -- the part inside the curly braces ({/}) -- should be executed in parallel by different threads.
IMPORTANT When writing your own code, ensure that you place the opening curly brace on a new line. Do not put it on the same line as the directive.
You can change the number of OpenMP threads by setting the environment variable OMP_NUM_THREADS or by using the omp_set_num_threads function before the parallel section in your program.
Try running the program:
If you run ./openmp_example a couple of times, you may notice that the printed numbers are not always in increasing order and will most likely vary across runs. This is because we didn't specify any sort of synchronization options, so OpenMP will not enforce any execution order. (More on that later.) It is also important to note that the variable thread_id is defined inside the parallel block, which means that each thread has its own copy of thread_id. In general with OpenMP, variables declared inside the parallel block will be private to each thread, but variables declared outside a parallel block will be shared across all threads. There are ways to override this, but more on that later.
Exercise 2: Vector Addition
Vector addition is a naturally parallel computation, since it's an elementwise operation (element i of the result vector does not depend on elements j != i), so it makes for a good first exercise. The v_add() functions inside omp_apps.c will store the sum of input vectors x and y into the result vector z. A first attempt at this might look like:
void
Try running the tests:
The testing framework will time the function execution for different thread counts. You should observe that this implementation performs worse as we increase the number of threads! Why?
The issue is that each thread is executing all of the code within the omp parallel block. If we have 8 threads, we'll actually be performing the same vector addition 8 times! Not only that, but various threads writing to the same variables in memory may cause a decrease in performance due to cache synchronization. Rather than have each thread run every iteration of the for loop, we need to split the for loop iterations across all the threads so each thread does only a portion of the work.
OpenMP has built-in functionality for dividing up the work of for loops among threads. To tell openMP to split up the work among multiple threads, you would use #pragma omp parallel for as seen below:
void
Note that there are no opening and closing brackets around the parallel section. The #pragma omp parallel for directive can only be placed directly before a for loop.
There are two ways that you can split up work:
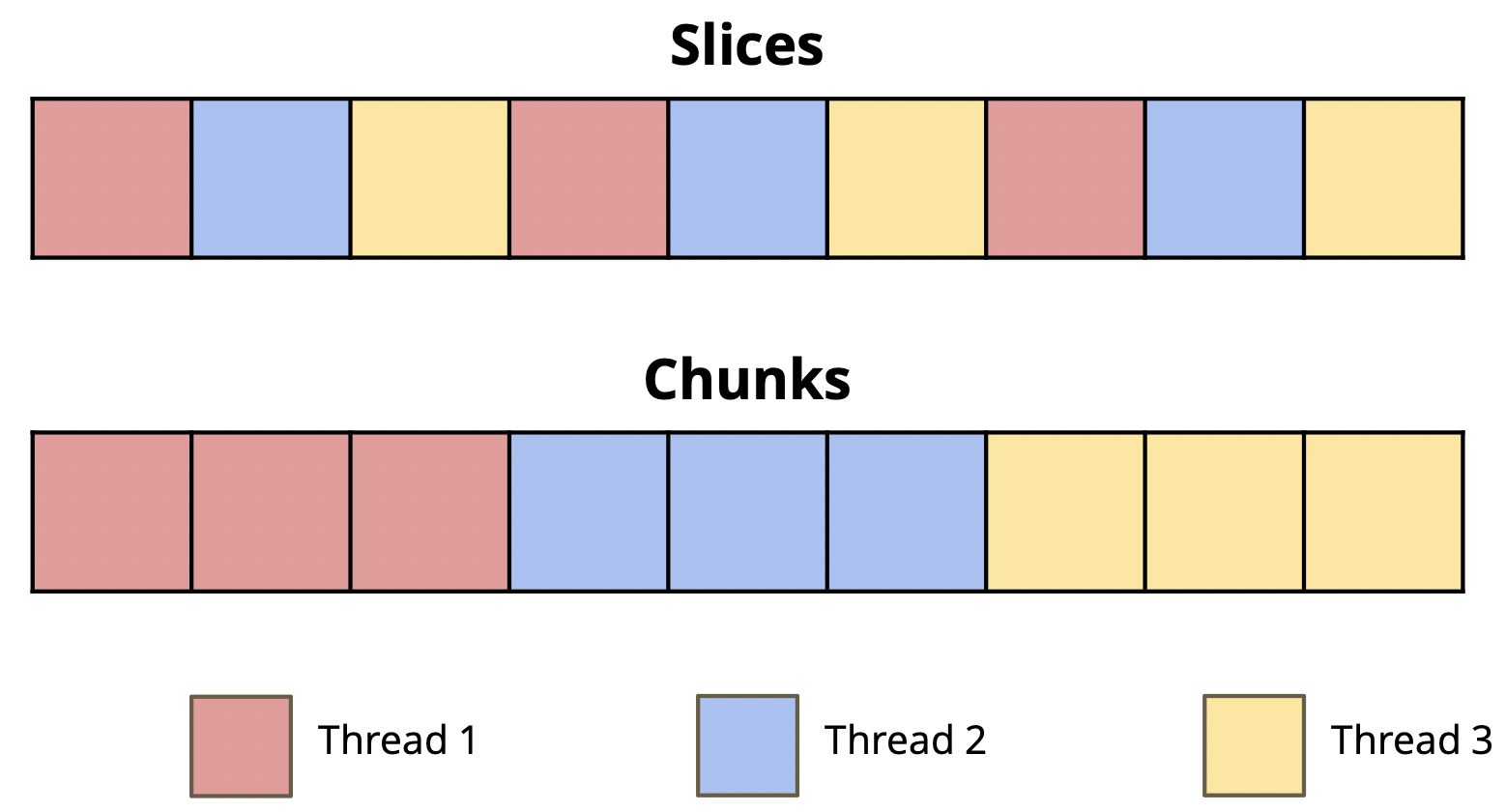
- Implement
v_add_optimized_adjacent()inex2.c, which separates the vectors into element-wise slices. - Implement
v_add_optimized_chunks()inex2.c, which separates the vectors into contiguous chunks.- As an example, if we have 3 threads, thread 0 will handle the first third of the elements in the array, thread 1 will handle the second third, and thread 3 will handle the last third. Remember to handle the "tail case" -- depending on your chunking logic, the last chunk may have slightly more or less elements than the others.
Your implementations should use the following 2 functions -- don't hardcode thread counts or thread IDs:
int omp_get_num_threads()- returns the current total number of OpenMP threads. Note that the number of threads will be1outside of an OpenMPparallelsection.int omp_get_thread_num()- returns the thread number of the current thread, commonly used as thread ID.
For this exercise, you CANNOT use #pragma omp parallel for. You must manually split up the work of the threads.
Remember that speedup may increase slower after a certain number of threads, since part of the whole program is not parallelizable.
Submission
Save, commit, and push your work, then submit to the Lab 7 assignment on Gradescope.