Samples of Data Loader
Some downsampled and augmented grayscale input images and their labels are illustrated below.
 |  |
|---|---|
 |  |
Architecture
We trained a model with the following architecture using AdamW with learning rate = 5e-4, weight_decay = 1e-4 and MSE loss for 50 epoches.
nn.Sequential(
nn.Conv2d(1, 8, 3),
nn.BatchNorm2d(8),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(8, 16, 3),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 3),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 64, 3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Flatten(),
nn.Linear(4928, 1024),
nn.ReLU(),
nn.Linear(1024, 256),
nn.ReLU(),
nn.Linear(256, 116)
)
Training and Validation Loss

Results
The following are a few good and bad outputs from our neural network. The images on the right show the generated keypoints. It seems that the network is more sensitive to the shadows around the faces than the actual facial features in some cases, resulting in keypoints that seem way off.
| Good Results | Bad Results |
|---|---|
 |  |
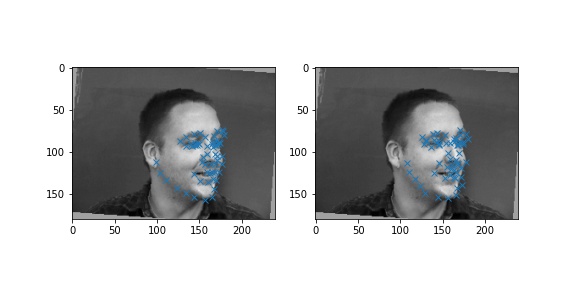 |  |
Features
These are the filters of the first convolutional layer from our network. They largely resemble line detectors.
