Linear classification
Consider the problem of finding a line which separates two data sets in two dimensions. These data sets may represent measurements about two kinds of populations (the first set might contain spam emails, while the second might contain legitimate ones). Each axis represents the frequency (say) of certain keywords in the email at hand — in our case, we look at two keywords, but in practice we might want to involve thousands of possible keywords.
We formalize this as follows. Each data point is given by its coordinates  and has a label
and has a label  which determines wether it is spam or not. A (possibly vertical) line in
which determines wether it is spam or not. A (possibly vertical) line in  -space, is parametrized by a vector
-space, is parametrized by a vector  , via the equation
, via the equation  . Such a line is said to correctly classify these two sets if all data points with
. Such a line is said to correctly classify these two sets if all data points with  fall on one side (hence
fall on one side (hence  ) and all the others on the other side (hence
) and all the others on the other side (hence  ). Hence, the affine inequalities on
). Hence, the affine inequalities on 

guarantee correct classification. The above can be used as constraints in an optimization problem, to derive an ‘‘optimal’’ line.
Once a line is found, a new point (for which we do not have a label) can be classified, by checking on which side of the line it falls. This is further discussed here.
 |
The image shows a line which separates two sets of points in |
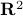 . An optimization problem can be formed to find such a line, even in more than two dimensions.
. An optimization problem can be formed to find such a line, even in more than two dimensions.