Portfolio Optimization via Linearly Constrained Least-Squares
We consider a universe of 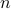 financial assets, in which we seek to invest over one time period. We denote by
financial assets, in which we seek to invest over one time period. We denote by  the vector containing the rates of return of each asset. A portfolio corresponds to a vector
the vector containing the rates of return of each asset. A portfolio corresponds to a vector  , where
, where 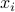 is the amount invested in asset
is the amount invested in asset 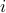 . In our simple model, we assume that ‘‘shorting’’ (borrowing) is allowed, that is, there are no sign restrictions on
. In our simple model, we assume that ‘‘shorting’’ (borrowing) is allowed, that is, there are no sign restrictions on  .
.
As explained here, the return of the portfolio is the scalar product  . We do not know the return vector
. We do not know the return vector  in advance. We assume that we know a reasonable prediction
in advance. We assume that we know a reasonable prediction  of . Of course, we cannot rely only on the vector only to make a decision, since the actual values in could fluctuate around . We can consider two simple ways to model the uncertainty on , which result in similar optimization problems.
of . Of course, we cannot rely only on the vector only to make a decision, since the actual values in could fluctuate around . We can consider two simple ways to model the uncertainty on , which result in similar optimization problems.
Mean-variance trade-off
A first approach assumes that is a random variable, with known mean and covariance matrix 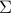 . If past values
. If past values  of the returns are known, we can use the following estimates
of the returns are known, we can use the following estimates

Note that, in practice, the above estimates for the mean and covariance matrix are very unreliable, and more sophisticated estimates should be used.
Then the mean value of the portfolio's return  takes the form
takes the form  , and its variance is
, and its variance is

We can strike a trade-off between the ‘‘performance’’ of the portfolio, measured by the mean return, against the ‘‘risk’’, measured by the variance, via the optimization problem

where 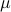 is our target for the nominal return. Since is positive semi-definite, that is, it can be written as
is our target for the nominal return. Since is positive semi-definite, that is, it can be written as  with
with  , the above problem is a linearly constrained least-squares.
, the above problem is a linearly constrained least-squares.
An ellipsoidal model
To model the uncertainty in , we can use the following deterministic model. We assume that the true vector lies in a given ellipsoid 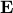 , but is otherwise unknown. We describe
, but is otherwise unknown. We describe  by its center and a ‘‘shape matrix’’ determined by some invertible matrix
by its center and a ‘‘shape matrix’’ determined by some invertible matrix 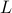 :
:

We observe that if  , then
, then  will be in an interval
will be in an interval ![[alpha_{rm min},alpha_{rm max}]](eqs/1484655024975793405-130.png) , with
, with

Using the Cauchy-Schwartz inequality, as well as the form of given above, we obtain that

Likewise,

For a given portfolio vector , the true return will lie in an interval ![[hat{r}^Tx - sigma(x) , hat{r}^Tx + sigma(x)]](eqs/6449612675730554809-130.png) , where
, where  is our ‘‘nominal’’ return, and
is our ‘‘nominal’’ return, and  is a measure of the ‘‘risk’’ in the nominal return:
is a measure of the ‘‘risk’’ in the nominal return:

We can formulate the problem of minimizing the risk subject to a constraint on the nominal return:
where is our target for the nominal return, and  . This is again a linearly constrained least-squares. Note that we obtain a problem that has exactly the same form as the stochastic model seen before.
. This is again a linearly constrained least-squares. Note that we obtain a problem that has exactly the same form as the stochastic model seen before.