Why do we take the log in GP?
For a posynomial 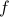 with values
with values
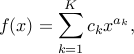
where 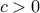 , we have
, we have

where 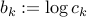 ,
, 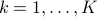 , and
, and 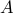 is the
is the 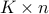 matrix with rows
matrix with rows 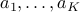 .
.
We may ask, why take the logarithm of ? The function with values

is convex already.
The answer is simply that the function 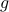 might take huge values, which might raise numerical problems. Taking its logarithm allows to recover smaller values.
might take huge values, which might raise numerical problems. Taking its logarithm allows to recover smaller values.
Note that the logarithm is concave, while is convex. A priori,  is not convex. It turns out that ‘‘the exponential beats the logarithm’’, in the sense that the latter functions’ concavity is not enough to destroy the convexity of the exponential.
is not convex. It turns out that ‘‘the exponential beats the logarithm’’, in the sense that the latter functions’ concavity is not enough to destroy the convexity of the exponential.