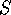 samples, a
technique called linear predictive coding (LPC) can be used to reduce the
samples in each segment to
samples, a
technique called linear predictive coding (LPC) can be used to reduce the
samples in each segment to 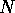 coefficients, in effect compressing the speech
by a factor of
coefficients, in effect compressing the speech
by a factor of 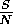 .
.
EECS20: Introduction to Real-Time Digital Systems
Lab09: Speech Coding
EECS20: Introduction to Real-Time Digital Systems
©1996 Regents of the University of California.
By K. H. Chiang, William T. Huang, Brian L. Evans.
URL: http://www-inst.eecs.berkeley.edu/~ee20
News: ucb.class.ee20
Five seconds of speech, quantized into eight bits and sampled at 8 kHz, requires 40 KB of memory, if stored. Suppose we wish to reduce the amount of storage space, at the expense of the quality of the speech.
Alternately, consider a situation in which we would like to transmit this speech over a communication channel, but the maximum bit rate permitted through the channel does not allow us to send the original speech signal.
One way to get around these problems is to use speech coding, as diagrammed in
Figure 1. First the speech is divided into segments, or
groups of samples. Assuming that each segment contains samples, a
technique called linear predictive coding (LPC) can be used to reduce the
samples in each segment to coefficients, in effect compressing the speech
by a factor of .

Figure 1: Largely content-free top level diagram.
Segmentation is easily accomplished by extracting groups of samples from
the vector containing the original speech sample. 50% overlapping of
successive segments is suggested, as in Figure 2.
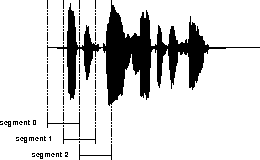
Figure 2: Segmentation with 50% overlapping.
The heart of the coding process is in the determination of the coefficients
for each segment. If we assume that the  th sample in a given speech segment
can be approximated by an appropriately scaled sum of the previous
th sample in a given speech segment
can be approximated by an appropriately scaled sum of the previous 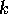 th
samples, the Matlab routine
th
samples, the Matlab routine lpc will give us the coefficients that
we're looking for.
Unfortunately, the description of the LPC algorithm is beyond the scope of this course. Suffice to say that if we constructed a DT system with these coefficients and gave the right input to the system, we would obtain a sequence of samples that would closely approximate the original sequence of samples.
Using the notation of the filter command, the b vector would be
[1] and the a vector would be the coefficients returned by the
lpc command.
What's the right input though? It turns out that for voiced speech, when the
vocal cords are forced to vibrate, a train of impulses as in
Figure 3 is the correct input. If the impulse train is supposed
to be at pitch 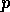 ,
,![]() the spacing between impulses is the ratio of the
sampling rate and the pitch:
the spacing between impulses is the ratio of the
sampling rate and the pitch: 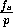 . All other samples in the train
are zeros.
. All other samples in the train
are zeros.
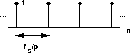
Figure 3: An impulse train with period .
samples in each segment, use the LPC command with an order of 9
[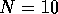 ] to get the coefficients of the corresponding DT system for that
segment.
] to get the coefficients of the corresponding DT system for that
segment.
filter command and an impulse train of pitch 100 Hz as input.
Since the output of the filter command is a DT signal with as many
samples as the input, make sure that your impulse train is of the correct
length. Sum the resulting filter outputs appropriately to get the
reconstructed speech and listen to the results.