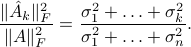Low-rank approximation of a matrix
Low-rank approximations
Link with PCA
Low-rank approximations
We consider a matrix 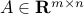 , with SVD given as in the SVD theorem:
, with SVD given as in the SVD theorem:
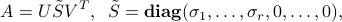
where the singular values are ordered in decreasing order, 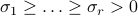 . In many applications it can be useful to approximate
. In many applications it can be useful to approximate 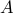 with a low-rank matrix.
with a low-rank matrix.
Example: Assume that contains the log-returns of 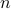 assets over
assets over 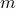 time periods, so that each column of is a time-series for a particular asset. Approximating by a rank-one matrix of the form
time periods, so that each column of is a time-series for a particular asset. Approximating by a rank-one matrix of the form 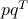 , with
, with 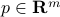 and
and 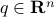 amounts to model the assets’ movements as all following the same pattern given by the time-profile
amounts to model the assets’ movements as all following the same pattern given by the time-profile 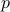 , each asset's movements being scaled by the components in
, each asset's movements being scaled by the components in 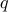 . Indeed, the
. Indeed, the 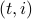 component of , which is the log-return of asset
component of , which is the log-return of asset 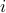 at time
at time 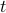 , then expresses as
, then expresses as 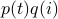 .
.
We consider the low-rank approximation problem
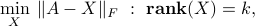
where 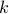 (
(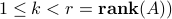 is given. In the above, we measure the error in the approximation using the Frobenius norm; using the largest singular value norm leads to the same set of solutions
is given. In the above, we measure the error in the approximation using the Frobenius norm; using the largest singular value norm leads to the same set of solutions 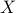 .
.
A best -rank approximation 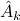 is given by zeroing out the
is given by zeroing out the  trailing singular values of , that is
trailing singular values of , that is

The minimal error is given by the Euclidean norm of the singular values that have been zeroed out in the process:
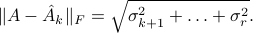
Sketch of proof: The proof rests on the fact that the Frobenius norm, is invariant by rotation of the input and output spaces, that is, 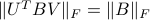 for any matrix
for any matrix 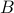 , and orthogonal matrices
, and orthogonal matrices 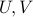 of appropriate sizes. Since the rank is also invariant, we can reduce the problem to the case when
of appropriate sizes. Since the rank is also invariant, we can reduce the problem to the case when 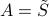 .
.
Example: low-rank approximation of a 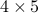 matrix.
matrix.
Link with Principal Component Analysis
Principal Component Analysis operates on the covariance matrix of the data, which is proportional to 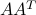 , and sets the principal directions to be the eigenvectors of that (symmetric) matrix. As noted here, the eigenvectors of are simply the left singular vectors of . Hence, both methods, the above approximation method and PCA, rely on the same tool, the SVD. The latter is a more complete approach as it also provides the eigenvectors of
, and sets the principal directions to be the eigenvectors of that (symmetric) matrix. As noted here, the eigenvectors of are simply the left singular vectors of . Hence, both methods, the above approximation method and PCA, rely on the same tool, the SVD. The latter is a more complete approach as it also provides the eigenvectors of 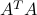 , which can be useful if we want to analyze the data in terms of rows instead of columns.
, which can be useful if we want to analyze the data in terms of rows instead of columns.
In particular, we can express the explained variance directly in terms of the singular values. In the context of visualization, the explained variance is simply the ratio to the total amount of variance in the projected data, to that in the original. More generally, when we are approximating a data matrix by a low-rank matrix, the explained variance compares the variance in the approximation to that in the original data. We can also interpret it geometrically, as the ratio of squared norm of the approximation matrix to that of the original matrix: