Least-squares and SVD
Set of solutions via the pseudo inverse
Sensitivity analysis
BLUE property
Set of solutions
The following theorem provides all the solutions (optimal set) of a least-squares problem.
The optimal set of the OLS problem
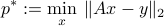
can be expressed as
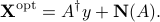
where 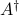 is the pseudo-inverse of
is the pseudo-inverse of 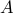 , and
, and 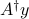 is the minimum-norm point in the optimal set. If is full column rank, the solution is unique, and equal to
is the minimum-norm point in the optimal set. If is full column rank, the solution is unique, and equal to
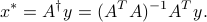
In general, the particular solution is the minimum-norm solution to the least-squares problem.
Proof: here.
Sensitivity analysis
We consider the situation where
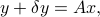
with
 the data matrix (known), with full column rank (hence
the data matrix (known), with full column rank (hence 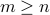 ).
).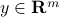 is the measurement (known).
is the measurement (known). is the vector to be estimated (unknown).
is the vector to be estimated (unknown).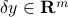 is a measurement noise or error (unknown).
is a measurement noise or error (unknown).
We can use OLS to provide an estimate 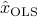 of
of  . The idea is to seek the smallest vector
. The idea is to seek the smallest vector 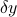 such that the above equation becomes feasible, that is,
such that the above equation becomes feasible, that is,
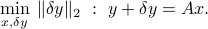
This leads to the OLS problem:
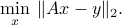
Since is full column rank, its SVD can be expressed as
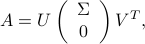
where 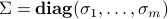 contains the singular values of , with
contains the singular values of , with 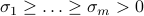 .
.
Since is full column rank, the solution 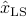 to the OLS problem is unique, and can be written as a linear function of the measurement vector
to the OLS problem is unique, and can be written as a linear function of the measurement vector 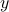 :
:
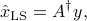
with the pseudo-inverse of . Again, since is full column rank,
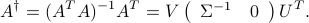
The OLS formulation provides an estimate 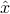 of the input such that the residual error vector
of the input such that the residual error vector 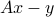 is minimized in norm. We are interested in analyzing the impact of perturbations in the vector , on the resulting solution . We begin by analyzing the absolute errors in the estimate, and then turn to the analysis of relative errors.
is minimized in norm. We are interested in analyzing the impact of perturbations in the vector , on the resulting solution . We begin by analyzing the absolute errors in the estimate, and then turn to the analysis of relative errors.
Set of possible errors
Let us assume a simple model of potential perturbations: we assume that belongs to a unit ball: 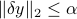 , where
, where 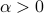 is given. We will assume
is given. We will assume 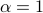 for simplicity; the analysis is easily extended to any
for simplicity; the analysis is easily extended to any 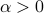 .
.
We have
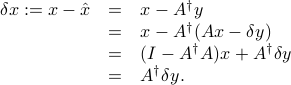
In the above we have exploited the fact that is a left inverse of , that is, 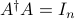 .
.
The set of possible errors on the solution 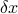 is then given by
is then given by
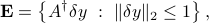
which is an ellipsoid centered at zero, with principal axes given by the singular values of . This ellipsoid can be interpreted as an ellipsoid of confidence for the estimate , with size and shape determined by the matrix 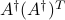 .
.
We can draw several conclusions from this analysis:
The largest absolute error in the solution that can result from a unit-norm, additive perturbation on
is of the order of 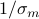 , where
, where 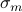 is the smallest singular value of .
is the smallest singular value of .The largest relative error is
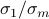 , the condition number of .
, the condition number of .
BLUE property
We now return to the case of an OLS with full column rank matrix .
Unbiased linear estimators
Consider the family of linear estimators, which are of the form
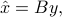
where 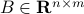 . To this estimator, we associate the error
. To this estimator, we associate the error
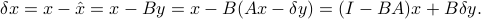
We say that the estimator (as determined by matrix 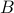 ) is unbiased if the first term is zero:
) is unbiased if the first term is zero:
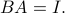
Unbiased estimators only exist when the above equation is feasible, that is, has a left inverse. This is equivalent to our condition that be full column rank. Since is a left-inverse of , the OLS estimator is a particular case of an unbiased linear estimator.
Best unbiased linear estimator
The above analysis leads to the following question: which is the best unbiased linear estimator? One way to formulate this problem is to assume that the perturbation vector is bounded in some way, and try to minimize the possible impact of such bounded errors on the solution.
Let us assume that belongs to a unit ball: 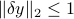 .
The set of resulting errors on the solution is then
.
The set of resulting errors on the solution is then
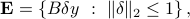
which is an ellipsoid centered at zero, with principal axes given by the singular values of . This ellipsoid can be interpreted as an ellipsoid of confidence for the estimate , with size and shape determined by the matrix 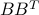 .
.
It can be shown that the OLS estimator is optimal in the sense that it provides the ‘‘smallest’’ ellipsoid of confidence among all unbiased linear estimators. Specifically:
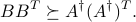
This optimality of the LS estimator is referred to as the BLUE (Best Linear Unbiased Estimator) property.