Properties
Existence: the range and rank of a matrix
Unicity: the nullspace of a matrix
Fundamental theorem of linear algebra
Matrix inverses
Consider the linear equation in  :
:
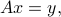
where 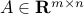 and
and 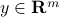 are given.
are given.
Existence: range and rank of a matrix
Range
The range (or, image) of a 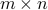 matrix
matrix 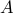 is defined as the following subset of
is defined as the following subset of 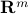 :
:
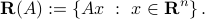
The range describes the vectors 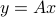 that can be attained in the output space by an arbitrary choice of a vector
that can be attained in the output space by an arbitrary choice of a vector  in the input space. The range is simply the span of the columns of .
in the input space. The range is simply the span of the columns of .
If 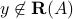 , we say that the linear equation
, we say that the linear equation 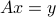 is infeasible.
is infeasible.
The matlab function orth accepts a matrix as input, and returns a matrix, the columns of which span the range of the matrix , and are mutually orthogonal. Hence, 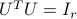 , where
, where  is the dimension of the range.
is the dimension of the range.
>> U = orth(A); % columns of U span the range of A, and U'*U = identity
Example:
Rank
The dimension of the range is called the rank of the matrix. As we will see later, the rank cannot exceed any one of the dimensions of the matrix : 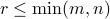 . A matrix is said to be full rank if
. A matrix is said to be full rank if 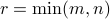 .
.
r = rank(A); % r is the rank of A
Note that the rank is a very ‘‘brittle’’ notion, in that small changes in the entries of the matrix can dramatically change its rank. Random matrices, such as ones generated using the Matlab command rand, are full rank. We will develop here a better, more numerically reliable notion.
Examples:
Range and rank of a simple matrix.
Full row rank matrices
The matrix is said to be full row rank (or, onto) if the range is the whole output space, . The name ‘‘full row rank’’ comes from the fact that the rank equals the row dimension of .
An equivalent condition for to be full row rank is that the square, 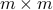 matrix
matrix 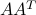 is invertible, meaning that it has full rank,
is invertible, meaning that it has full rank, 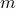 . Proof.
. Proof.
Unicity: nullspace of a matrix
Nullspace
The nullspace (or, kernel) of a matrix is the following subspace of 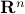 :
:
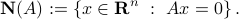
The nullspace describes the ambiguity in given : any 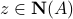 will be such that
will be such that 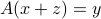 , so cannot be determined by the sole knowledge of
, so cannot be determined by the sole knowledge of 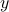 if the nullspace is not reduced to the singleton
if the nullspace is not reduced to the singleton 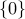 .
.
The matlab function null accepts a matrix as input, and returns a matrix, the columns of which span the nullspace of the matrix , and are mutually orthogonal. Hence, , where is the dimension of the range.
U = null(A); % columns of A span the nullspace of A, and U'*U = I
Example:
Nullspace of a simple matrix.
Full column rank matrices
The matrix is said to be full column rank (or, one-to-one) if its nullspace is the singleton . In this case, if we denote by 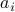 the
the 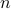 columns of , the equation
columns of , the equation
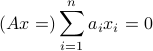
has 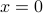 as the unique solution. Hence, is one-to-one if and only if its columns are independent.
as the unique solution. Hence, is one-to-one if and only if its columns are independent.
The term ‘‘one-to-one’’ comes from the fact that for such matrices, the condition 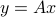 uniquely determines , since
uniquely determines , since 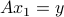 and
and 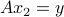 implies
implies 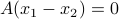 , so that the solution is unique:
, so that the solution is unique: 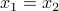 . The name ‘‘full column rank’’ comes from the fact that the rank equals the column dimension of .
. The name ‘‘full column rank’’ comes from the fact that the rank equals the column dimension of .
An equivalent condition for to be full column rank is that the square, 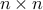 matrix
matrix 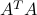 is invertible, meaning that it has full rank, . (Proof)
is invertible, meaning that it has full rank, . (Proof)
Example: Nullspace of a transpose incidence matrix.
Fundamental theorem of linear algebra
A basic result of linear algebra is that the nullspace of a matrix and the range of the transpose matrix are orthogonal sets, in the sense that any two vectors, each chosen in one of the sets, are orthogonal. Further, their dimensions sum up to . That is, the two sets form an orthogonal decomposition of the whole space.
Let . The sets 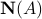 and
and 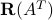 form an orthogonal decomposition of , in the sense that any vector can be written as
form an orthogonal decomposition of , in the sense that any vector can be written as
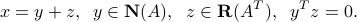
Proof: the proof uses the Singular Value Decomposition seen later.
Example: XXX.
We will see later that the rank of a matrix is equal to that of its transpose. Thus, a consequence of the theorem is that
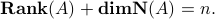
The interpretation of the above is that is the number of degrees of freedom in input ;  gives the number of degrees of freedom that remain in the output, while
gives the number of degrees of freedom that remain in the output, while 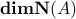 counts the number of dimensions of that are ‘‘crushed’’ to zero by the mapping
counts the number of dimensions of that are ‘‘crushed’’ to zero by the mapping 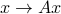 .
.
Matrix inverses
Left and right inverses
It can be shown that a matrix is full row rank if and only if it has a right inverse, that is, there exist a matrix 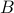 such that
such that 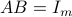 , where
, where 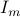 is the identity matrix.
is the identity matrix.
It can be shown that a matrix is full column rank if and only if it has a left inverse, that is, there exist a matrix such that 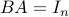 , where
, where 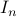 is the identity matrix. Hence, for a one-to-one matrix, the equation has always a unique solution,
is the identity matrix. Hence, for a one-to-one matrix, the equation has always a unique solution, 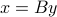 .
.
Invertible matrices
If square matrix is full row rank if and only if it is full row rank, and vice-versa. In this case, we simply say that the matrix is invertible. Then, there exist a unique left- and right inverse, and both are equal to a matrix called the inverse, and denoted 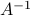 .
The inverse satisfies
.
The inverse satisfies 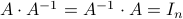 .
.
For an invertible matrix, the nullspace is a the zero subspace , and the range is the whole space, . In addition, the equation then always has a unique solution for every .
There is a closed-form expression of the inverse, based on the notion of determinant. This expression is useful for theoretical reasons but never used in practice. Later we will see how to compute the matrix inverse in a numerically more efficient way.
A useful property is the expression of the inverse of a product of two square, invertible matrices 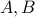 :
: 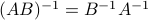 .
.