Variants of the Least-Squares Problem
Linearly-constrained least-squares
Minimum-norm solutions to linear equations
Regularized least-squares
Linearly constrained least-squares
Definition
An interesting variant of the ordinary least-squares problem involves equality constraints on the decision variable  :
:

where 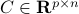 , and
, and 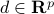 are given.
are given.
Examples:
Solution
We can express the solution by first computing the nullspace of 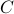 . Assuming that the feasible set of the constrained LS problem is not empty, that is,
. Assuming that the feasible set of the constrained LS problem is not empty, that is, 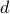 is in the range of , this set can be expressed as
is in the range of , this set can be expressed as

where 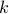 is the dimension of the nullspace of ,
is the dimension of the nullspace of , 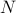 is a matrix whose columns span the nullspace of , and
is a matrix whose columns span the nullspace of , and 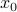 is a particular solution to the equation
is a particular solution to the equation 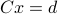 .
.
Expressing in terms of the free variable  , we can write the constrained problem as an unconstrained one:
, we can write the constrained problem as an unconstrained one:

where  , and
, and  .
.
Minimum-norm solution to linear equations
A special case of linearly constrained LS is

in which we implicitly assume that the linear equation in : 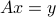 , has a solution, that is,
, has a solution, that is, 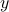 is in the range of
is in the range of 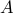 .
.
The above problem allows to select a particular solution to a linear equation, in the case when there are possibly many, that is, the linear system is under-determined.
As seen here, when is full row rank, that is, the matrix 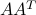 is invertible, the above has the closed-form solution
is invertible, the above has the closed-form solution

Examples: Control positioning of a mass.
Regularized least-squares
In the case when the matrix in the OLS problem is not full column rank, the closed-form solution cannot be applied. A remedy often used in practice is to transform the original problem into one where the full column rank property holds.
The regularized least-squares problem has the form

where 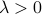 is a (usually small) parameter.
is a (usually small) parameter.
The regularized problem can be expressed as an ordinary least-squares problem, where the data matrix is full column rank. Indeed, the above problem can be written as the ordinary LS problem

where

The presence of the identity matrix in the  matrix
matrix  ensures that it is full (column) rank.
ensures that it is full (column) rank.
Solution
Since the data matrix in the regularized LS problem has full column rank, the formula seen here applies. The solution is unique, and given by

For 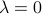 , we recover the ordinary LS expression that is valid when the original data matrix is full rank.
, we recover the ordinary LS expression that is valid when the original data matrix is full rank.
The above formula explains one of the motivations for using regularized least-squares in the case of a rank-deficient matrix : if , but is small, the above expression is still defined, even if is rank-deficient.
Weighted regularized least-squares
Sometimes, as in kernel methods, we are led to problems of the form

where  is positive definite (that is,
is positive definite (that is,  for every non-zero ). The solution is again unique and given by
for every non-zero ). The solution is again unique and given by
