6.6 Exact Inference in Bayes Nets
Inference is the problem of finding the value of some probability distribution \(P(Q_1 \dots Q_k | e_1 \dots e_k)\), as detailed in the Probabilistic Inference section at the beginning of the note. Given a Bayes Net, we can solve this problem naively by forming the joint PDF and using Inference by Enumeration. This requires the creation of and iteration over an exponentially large table.
6.6.1 Variable Elimination
An alternate approach is to eliminate hidden variables one by one. To eliminate a variable \(X\), we:
- Join (multiply together) all factors involving \(X\).
- Sum out \(X\).
A factor is defined simply as an unnormalized probability. At all points during variable elimination, each factor will be proportional to the probability it corresponds to, but the underlying distribution for each factor won’t necessarily sum to 1 as a probability distribution should. The pseudocode for variable elimination is here:

Let’s make these ideas more concrete with an example. Suppose we have a model as shown below, where \(T\), \(C\), \(S\), and \(E\) can take on binary values. Here, \(T\) represents the chance that an adventurer takes a treasure, \(C\) represents the chance that a cage falls on the adventurer given that they take the treasure, \(S\) represents the chance that snakes are released if an adventurer takes the treasure, and \(E\) represents the chance that the adventurer escapes given information about the status of the cage and snakes.
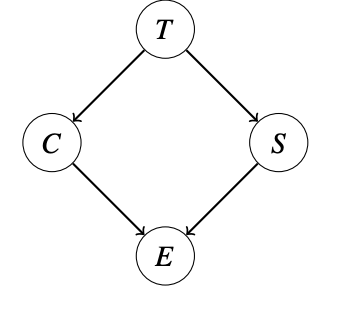
In this case, we have the factors \(P(T)\), \(P(C|T)\), \(P(S|T)\), and \(P(E|C,S)\). Suppose we want to calculate \(P(T | +e)\). The inference by enumeration approach would be to form the 16-row joint PDF \(P(T, C, S, E)\), select only the rows corresponding to +e, then sum out \(C\) and \(S\) and finally normalize.
The alternate approach is to eliminate \(C\), then \(S\), one variable at a time. We’d proceed as follows:
Join (multiply) all the factors involving \(C\), forming \(f_1(C, +e, T, S) = P(C|T) \cdot P(+e|C, S)\). Sometimes this is written as \(P(C, +e | T, S)\).
Sum out \(C\) from this new factor, leaving us with a new factor \(f_2(+e, T, S)\), sometimes written as \(P(+e | T, S)\).
Join all factors involving \(S\), forming \(F_3(+e, S, T)=P(S|T) \cdot f_2(+e, T, S)\), sometimes written as \(P(+e, S | T)\).
Sum out \(S\), yielding \(f_4(+e, T)\), sometimes written as \(P(+e | T)\).
Join the remaining factors, which gives \(f_5(+e, T) = f_4(+e, T) \cdot P(T)\).
Once we have \(f_5(+e, T)\), we can easily compute \(P(T|+e)\) by normalizing.
When writing a factor that results from a join, we can either use factor notation like \(f_1(C, +e, T, S)\), which ignores the conditioning bar and simply provides a list of variables that are included in this factor.
Alternatively, we can write \(P(C, +e | T, S)\), even if this is not guaranteed to be a valid probability distribution (e.g. the rows might not sum to 1). To derive this expression mechanically, note that all variables on the left-hand side of the conditioning bars in the original factors (here, \(C\) in \(P(C|T)\) and \(E\) in \(P(E|C,S)\)) stay on the left-hand side of the bar. Then, all remaining variables (here, \(T\) and \(S\)) go on the right-hand side of the bar.
This approach to writing factors is grounded in repeated applications of the chain rule. In the example above, we know that we can’t have a variable on both sides of the conditional bar. Also, we know:
\[P(T, C, S, +e) = P(T) P(S | T) P(C | T) P(+e | C, S) = P(S, T) P(C | T) P(+e | C, S)\]and so:
\[P(C | T) P(+e | C, S) = \frac{P(T, C, S, +e)}{P(S, T)} = P(C, +e | T, S)\]While the variable elimination process is more involved conceptually, the maximum size of any factor generated is only 8 rows instead of 16, as it would be if we formed the entire joint PDF.
An alternate way of looking at the problem is to observe that the calculation of \(P(T|+e)\) can either be done through inference by enumeration as follows:
\[\alpha \sum_s{\sum_c{P(T)P(s|T)P(c|T)P(+e|c,s)}}\]or by variable elimination as follows:
\[\alpha P(T)\sum_s{P(s|T)\sum_c{P(c|T)P(+e|c,s)}}\]We can see that the equations are equivalent, except that in variable elimination we have moved terms that are irrelevant to the summations outside of each summation!
As a final note on variable elimination, it’s important to observe that it only improves on inference by enumeration if we are able to limit the size of the largest factor to a reasonable value.